让终端用户能够以交互方式教机器人执行新任务,这是成功将其集成到实际应用中的关键能力。例如,用户可能想教机器狗表演新技巧,或者教机械手如何根据用户偏好整理午餐盒。在大量互联网数据上预先训练的大型语言模型(LLM) 的最新进展为实现这一目标提供了一条有希望的道路。事实上,研究人员已经探索了利用 LLM 进行机器人技术的各种方式,从分步规划和面向目标的对话到机器人代码编写代理。
虽然这些方法赋予了新的组合泛化模式,但它们专注于使用语言将现有控制原语库中的新行为链接在一起,这些原语要么是手动设计的,要么是先验学习的。尽管拥有关于机器人运动的内部知识,但由于相关训练数据的可用性有限,LLM 很难直接输出低级机器人命令。因此,这些方法的表达受到可用原语广度的瓶颈,而原语的设计通常需要广泛的专业知识或大量的数据收集。
在“机器人技能综合的语言到奖励”中,我们提出了一种方法,使用户能够通过自然语言输入教机器人新动作。为此,我们利用奖励函数作为弥合语言和低级机器人动作之间差距的界面。我们假设奖励函数为此类任务提供了理想的界面,因为它们具有丰富的语义、模块化和可解释性。它们还通过黑盒优化或强化学习 (RL) 提供与低级策略的直接连接。我们开发了一个语言到奖励系统,该系统利用 LLM 将自然语言用户指令转换为奖励指定代码,然后应用MuJoCo MPC来找到最大化生成的奖励函数的最佳低级机器人动作。我们使用四足机器人和灵巧机械手机器人在模拟中展示了我们的语言到奖励系统在各种机器人控制任务中的应用。我们进一步在物理机器人机械手上验证了我们的方法。
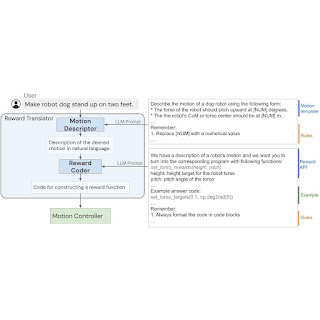
语言到奖励系统由两个核心组件组成:(1)奖励转换器和(2)运动控制器。奖励转换器 将用户的自然语言指令映射到以Python 代码表示的奖励函数。运动控制器使用滚动优化算法优化给定的奖励函数,以找到最佳的低级机器人动作,例如应施加到每个机器人电机的扭矩量。
由于预训练数据集中缺少数据,LLM 无法直接生成低级机器人动作。我们建议使用奖励函数来弥合语言和低级机器人动作之间的差距,并从自然语言指令中实现新颖的复杂机器人动作。
奖励翻译器:将用户指令翻译成奖励函数
奖励翻译器模块的构建目标是将自然语言用户指令映射到奖励函数。奖励调整高度特定于领域,需要专业知识,因此当我们发现在通用语言数据集上训练的 LLM 无法直接为特定硬件生成奖励函数时,我们并不感到惊讶。为了解决这个问题,我们应用了LLM 的上下文学习能力。此外,我们将奖励翻译器拆分为两个子模块:运动描述符和奖励编码器。
运动描述符
首先,我们设计了一个运动描述符,它可以解释用户的输入,并按照预定义的模板将其扩展为所需机器人运动的自然语言描述。此运动描述符将可能模棱两可或模糊的用户指令转变为更具体、更具描述性的机器人运动,从而使奖励编码任务更加稳定。此外,用户通过运动描述字段与系统进行交互,因此与直接显示奖励函数相比,这也为用户提供了更易于解释的界面。
为了创建运动描述符,我们使用 LLM 将用户输入转换为所需机器人运动的详细描述。我们设计提示来指导 LLM 输出具有适当细节和格式的运动描述。通过将模糊的用户指令转换为更详细的描述,我们能够更可靠地使用我们的系统生成奖励函数。这个想法也可能更广泛地应用于机器人任务之外,并且与内心独白和思路链提示相关。
奖励编码器
在第二阶段,我们使用与 Motion Descriptor 相同的 LLM 作为奖励编码器,将生成的动作描述转换为奖励函数。奖励函数使用 Python 代码表示,以利用 LLM 对奖励、编码和代码结构的知识。
理想情况下,我们希望使用 LLM 直接生成奖励函数R ( s , t ),将机器人状态s和时间t映射到标量奖励值。但是,从头开始生成正确的奖励函数对于 LLM 来说仍然是一个具有挑战性的问题,纠正错误需要用户理解生成的代码以提供正确的反馈。因此,我们预先定义了一组常用于相关机器人的奖励项,并允许 LLM 组合不同的奖励项来制定最终的奖励函数。为了实现这一点,我们设计了一个提示来指定奖励项并指导 LLM 为任务生成正确的奖励函数。
奖励转换器的内部结构,其任务是将用户输入映射到奖励函数。
运动控制器:将奖励函数转化为机器人动作
运动控制器采用奖励转换器生成的奖励函数,并合成一个将机器人观察结果映射到低级机器人动作的控制器。为此,我们将控制器合成问题公式化为马尔可夫决策过程(MDP),可以使用不同的策略来解决,包括 RL、离线轨迹优化或模型预测控制(MPC)。具体来说,我们使用基于MuJoCo MPC (MJPC) 的开源实现。
MJPC 已展示出多种行为的交互式创建,例如腿部运动、抓握和手指步态,同时支持多种规划算法,例如迭代线性二次高斯(iLQG) 和预测采样。更重要的是,MJPC 中的频繁重新规划增强了其对系统不确定性的鲁棒性,并与 LLM 结合使用时可实现交互式运动合成和校正系统。
示例
机器狗
在第一个示例中,我们将语言到奖励系统应用于模拟四足机器人,并教它执行各种技能。对于每项技能,用户将向系统提供简明的指令,然后系统将使用奖励函数作为中间接口来合成机器人动作。
灵巧机械手
然后,我们将语言到奖励系统应用于灵巧操纵机器人,以执行各种操纵任务。灵巧操纵器有 27 个自由度,控制起来非常具有挑战性。许多这些任务需要超越抓握的操纵技能,这使得预先设计的原语难以发挥作用。我们还提供了一个示例,用户可以交互地指示机器人将苹果放在抽屉里。
在真实机器人上进行验证
我们还使用现实世界中的操控机器人执行拾取物体和打开抽屉等任务来验证语言到奖励方法。为了在运动控制器中执行优化,我们使用AprilTag(基准标记系统)和F-VLM(开放词汇对象检测工具)来识别桌子和被操控物体的位置。
结论
在这项工作中,我们描述了一种通过奖励函数将 LLM 与机器人连接起来的新范例,该范例由低级模型预测控制工具 MuJoCo MPC 提供支持。使用奖励函数作为接口使 LLM 能够在语义丰富的空间中工作,从而发挥 LLM 的优势,同时确保生成的控制器的表达能力。为了进一步提高系统的性能,我们建议使用结构化运动描述模板来更好地从 LLM 中提取有关机器人运动的内部知识。我们在两个模拟机器人平台和一个真实机器人上演示了我们提出的系统,用于运动和操纵任务。
致谢
我们要感谢我们的合著者 Nimrod Gileadi、Chuyuan Fu、Sean Kirmani、Kuang-Huei Lee、Montse Gonzalez Arenas、Hao-Tien Lewis Chiang、Tom Erez、Leonard Hasenclever、Brian Ichter、Ted Xiao、Peng Xu、Andy Zeng、Tingnan Zhang、Nicolas Heess、Dorsa Sadigh、Jie Tan 和 Yuval Tassa 在项目各个方面提供的帮助和支持。我们还要感谢 Ken Caluwaerts、Kristian Hartikainen、Steven Bohez、Carolina Parada、Marc Toussaint 以及 Google DeepMind 团队的反馈和贡献。
评论