了解我们如何重新设计 Web 的模型加载代码,以克服一些内存限制,并使用我们的跨平台推理框架在浏览器中运行更大(7B+)的 LLM。
大型语言模型 (LLM) 是一种了不起的工具,它为人类与计算机和设备的交互提供了新的方式。这些模型通常在专门的服务器群上运行,请求和响应通过互联网连接传输。完全在设备上运行模型是一种有吸引力的替代方案,因为这样可以消除服务器成本,确保更高程度的用户隐私,甚至允许离线使用。然而,这样做是对机器学习基础设施的真正压力测试:即使是“小型”LLM 通常也有数十亿个参数和以千兆字节 (GB) 为单位的大小,这很容易使内存和计算能力过载。
今年早些时候,Google AI Edge 的 MediaPipe(一种高效的设备管道框架)推出了一种新的实验性跨平台 LLM 推理 API,该 API 可以利用设备 GPU 在 Android、iOS 和 Web 上运行小型 LLM,并实现最佳性能。在发布时,它能够完全在设备上运行四个公开可用的 LLM:Gemma、Phi 2、Falcon和Stable LM。这些模型的大小从 10 亿到 30 亿个参数不等。
当时,这些也是我们的系统能够在浏览器中运行的最大模型。为了实现如此广泛的平台覆盖,我们的系统首先针对移动设备。然后,我们将其升级为在浏览器中运行,由于升级对使用和内存的额外限制,速度保持不变,但也增加了复杂性。加载更大的模型会超出这些新的内存限制(下面将详细讨论)。此外,我们的缓解选项受到两个关键系统要求的极大限制:(1)一个可以适应许多模型的单一库和(2)能够使用.tflite我们许多产品中使用的单一文件格式。
今天,我们迫不及待地想分享我们 Web API的更新。这包括针对 Web 重新设计我们的模型加载系统以应对这些挑战,这使我们能够运行更大的模型,如Gemma 1.1 7B 。这个 8.6GB 的文件包含 70 亿个参数,比我们之前在浏览器中运行的任何模型都大几倍,其响应质量的提升也相应显著 — 请在MediaPipe Studio中亲自尝试一下!
用户与浏览器中运行的 Gemma 1.1 7B 之间的对话视频。用户询问生日贺卡信息创意,得到了几个模板作为回应。提供了后续细节,然后模型将其纳入其中。
在网上运行法学硕士
Google AI Edge 的MediaPipe从根本上来说是跨平台的,因此我们的大多数代码都是用C++编写的,可以很好地针对许多目标平台和架构进行编译。为了在浏览器中运行它,我们将整个代码库(所有非特定于 Web 的内容,包括依赖项)编译为WebAssembly,这是一种特殊的汇编代码,可以在所有主流浏览器中高效运行。这为我们提供了出色的性能和可扩展性,但也带来了一些额外的限制,因为浏览器在沙盒虚拟机中运行 WebAssembly(即模拟单独的物理计算机)。
值得注意的一个细节是,虽然 WebAssembly 会影响我们的 C++ 代码和 CPU 内存限制,但它不会限制我们的 GPU 功能。这是因为我们使用WebGPU API 执行所有与 GPU 相关的任务,该 API 旨在在浏览器中本地运行,让我们能够比以往更直接地访问 GPU 及其计算功能。为了获得最佳性能,我们的机器学习推理引擎会上传模型权重并完全在 GPU 上运行模型操作。
克服内存限制
相比之下,从硬盘或网络加载 LLM 时,原始数据必须经过多层才能到达 GPU:
文件读取内存
JavaScript 内存
WebAssembly 内存
WebGPU 设备内存
具体来说,我们使用基于浏览器的文件读取 API 将原始数据导入 JavaScript,将其传递到我们的 C++ WebAssembly 内存,最后将其上传到 WebGPU,所有内容将在那里运行。我们需要考虑这些层中的每一层都有内存限制(如下所述),因此我们设计了系统架构来适应这些限制。
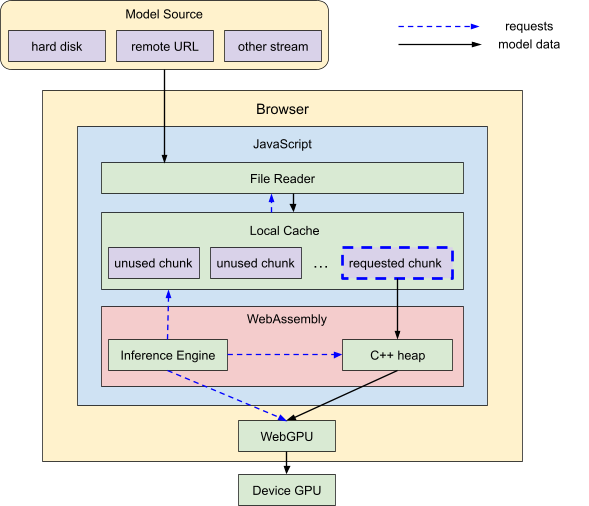
MediaPipeLLM2-Hero建筑
加载系统架构。WebAssembly 推理引擎指示将模型数据块从本地缓存移动到 C++ 内存,然后再移动到 GPU。根据需要,本地缓存会从 JavaScript 文件读取器请求其他模型数据,该文件读取器会从模型源流式传输这些数据。
WebGPU 设备内存
WebGPU 设备限制是特定于硬件的,但值得庆幸的是,大多数现代笔记本电脑和台式机都有足够的 GPU 内存供我们使用。因此,我们专注于消除其他三个内存限制(所有 CPU),以将其作为唯一真正的限制。
文件读取内存
我们之前的 MediaPipe Web API 在加载数据时大量使用ArrayBuffer等 JavaScript 原语,但其中许多原语无法支持超过 2GB 的大小。对于最初的 Web LLM 发布,我们通过创建依赖于更灵活对象(如ReadableStreamDefaultReader )的自定义数据复制例程来解决 2GB 的限制。现在,对于我们的最新更新,我们在此之前的工作基础上,将我们的海量文件分解成更小的块,当我们将它们复制到工作内存中时,这些块会根据需要进行流式传输。
WebAssembly 内存
我们面临的主要技术挑战是 WebAssembly 目前使用32 位整数(从 0 到 2 32 -1)来索引其内存空间中的地址,如果我们使用超过 2 32字节(≅ 4.3GB),索引方案就会溢出。事实上,即使要访问这么多内存也需要一些变通方法。
幸运的是,我们可以利用 LLM 的结构。LLM 涉及很多部分,但二进制大小的大部分都位于转换器堆栈中。这是一堆形状相似的模型,它们在连续的层中逐层运行。
MediaPipeLLM3-堆栈
Transformer 堆栈。输入作为第 1 层的输入进入堆栈,第 1 层的输出作为第 2 层的输入。此过程持续进行,直到最后一层的输出离开堆栈。
Gemma 1.1 7B 有 28 个这样的层,这意味着如果我们能够一次将一个层加载到 WebAssembly 内存中,那么这一步的内存使用率应该会提高 28 倍。因此,我们将同步加载管道改为异步加载管道,其中 C++ 代码调用 JavaScript 依次请求并等待所需的每个权重缓冲区。
实际上,Gemma 1.1 7B 加载的结果甚至比预期的还要好:层本身包含许多权重缓冲区,这些缓冲区都不是很大,因此通过按需加载单个权重缓冲区,我们的 Transformer 堆栈加载的峰值 WebAssembly 内存使用量现在还不到原来的 1%!
JavaScript 内存
然而,这些升级有一个主要缺点:我们现在在加载过程中通过一次扩展扫描来解析庞大的模型文件,这不允许我们按需“跳转”到文件中的特定位置(通常俗称随机访问)。这意味着我们加载片段的顺序现在很重要。如果我们从文件末尾请求缓冲区,那么我们就不能从开头请求缓冲区。
明确的解决方案是让模型权重按照加载代码要求的顺序存储。但完全保证这一点的唯一方法是将排序作为模型格式的一部分,或者让我们的内部加载代码能够动态地重新排列自身以匹配模型排序。这些都是长期解决方案,所以现在,我们需要一个备用计划,以便我们能够处理任意的模型权重排序。
多次扫描文件会非常慢,而且我们知道我们永远不需要加载相同的数据两次,所以我们创建一个临时的本地缓存。在扫描数据时,我们会将其分成小块,保留尚未使用的数据并丢弃其余数据。这种方法可以优雅地降级:如果模型的排序是理想的,则不会缓存任何内容,只有当排序完全“向后”时,我们才需要临时缓存整个文件。后一种情况在实践中永远不会发生,但即使发生了,我们的解决方案仍然适用于 7B 参数大小的模型,因为我们的本地缓存保存在 JavaScript 内存中,大多数浏览器为此提供了相当宽松的每个选项卡限制(Chrome 中约为 16GB)。
下一步
为了消除与 CPU 端内存相关的摩擦,减少内存使用量的另一个解决方案就是制作更小的模型。这通常是通过应用更积极的量化策略来实现的,这意味着保持相同数量的权重,但将这些权重压缩成更少的位。对于我们早期的 Gemma 1.1 2B 模型,我们发布了一个“int4”版本,该版本在保持质量的同时,大小只有原始“int8”版本的一半。我们希望很快在 Gemma 1.1 7B 中重复这一壮举。
除了缓解内存压力和扩大模型覆盖范围外,我们还在不断优化性能并添加令人兴奋的新功能,例如动态 LoRA 支持,可进行微调和动态自定义。特别是,多模式支持和取消是我们很乐意提供的两个热门功能请求。我们正在努力将Gemma 2也纳入其中 — 敬请期待更多更新!
致谢
我们要感谢为这一突破做出贡献的每一个人:Clark Duvall、Lin Chen、Sebastian Schmidt、Pulkit Bhuwalka、Mark Sherwood、Mig Gerard、Zichuan Wei、Linkun Chen、Yu-hui Chen、Juhyun Lee、Ho Ko、Kristen Wright、Sachin Kotwani、Cormac Brick、Lu Wang、Chuo-Ling Chang、Ram Iyengar 和 Matthias Grundmann。
评论