Google Ads基础架构在名为Napa 的内部数据仓库上运行。数十亿条报告查询在 Napa 中存储的表上运行,这些查询为广告客户用来衡量广告系列效果的关键仪表板提供支持。这些表包含广告效果记录,这些记录使用特定客户和与其关联的广告系列标识符作为键。键是用于将广告记录与特定客户和广告系列(例如,)关联以及进行高效检索的令牌customer_id。campaign_id一条记录包含数十个键,因此客户使用报告查询来指定过滤数据以了解广告效果所需的键(例如按地区、设备和点击次数等指标)。这个问题的挑战性在于数据是倾斜的,因为查询需要不同程度的努力才能得到回答,并且有严格的延迟预期。具体而言,某些查询需要使用数百万条记录,而其他查询只需几条记录即可回答。
为此,我们在VLDB 2023上发表的“ Napa 中并行查询执行的渐进分区”中描述了 Napa 数据仓库如何确定回答报告查询所需的机器资源量,同时满足严格的延迟目标。我们引入了一种新的渐进式查询分区算法,该算法可以在存在复杂数据偏差的情况下并行执行查询,从而在几毫秒内始终保持良好的性能。最后,我们展示了 Napa 如何让 Google Ads 基础架构每天处理数十亿次查询。
查询处理挑战
当客户输入报告查询时,主要的挑战是确定如何有效地并行化查询。Napa 的并行化技术将查询分解为均匀分布在可用机器上的均匀部分,然后并行处理这些部分以显著减少查询延迟。这是通过估计与指定键相关的记录数,并将大致相等的工作量分配给机器来实现的。然而,这种估计并不完美,因为审查所有记录所需的工作量与回答查询所需的工作量相同。处理能力明显高于其他机器的机器会导致运行时偏差和性能不佳。每台机器还需要有足够的工作,因为不必要的并行性会导致基础设施利用不足。最后,并行化必须是每个查询的决策,必须近乎完美地执行数十亿次,否则查询可能会错过严格的延迟要求。
下面的报表查询示例提取由键(即customer_id和campaign_id)表示的记录,然后SUM(cost)从广告客户表中计算聚合(即)。在此示例中,记录数量太大,无法在单台机器上处理,因此 Napa 需要使用后续键(例如adgroup_id)进一步分解记录集合,以实现工作的平均分配。值得注意的是,在 PB 级,并行化所需的数据统计量可能达到几 TB。这意味着问题不仅在于收集大量元数据,还在于如何管理它。
选择客户 ID、活动 ID、SUM(费用)
来自 advertiser_table
其中 customer_id 位于(1,7,...,x)
AND campaign_id 在 (10, 20, ..., y) 中
按客户ID和活动ID分组;
此报告查询示例提取由键(即customer_id和campaign_id)表示的记录,然后SUM(cost)从广告客户表计算聚合(即)。查询工作量由查询中包含的键决定。属于具有较大广告系列的客户的键可能涉及数百万条记录,因为数据量与广告系列的规模直接相关。基于键匹配记录的这种差异反映了数据的偏差,这使得查询处理成为一个具有挑战性的问题。
有效的解决方案可以最大限度地减少所需的元数据量,主要将精力集中在键空间的倾斜部分以有效地对数据进行分区,并在分配的时间内很好地工作。例如,如果查询延迟为几百毫秒,则分区不应超过几十毫秒。最后,并行化过程应确定何时达到考虑查询延迟预期的最佳分区。为此,我们开发了一种渐进式分区算法,我们将在本文后面进行描述。
管理数据洪流
Napa 中的表会不断更新,因此我们使用日志结构合并森林(LSM 树) 来组织大量的表更新。LSM 是一个排序数据森林,它按时间顺序组织,使用B 树索引来支持高效的键查找查询。B 树以分层方式存储子树的摘要信息。每个 B 树节点记录每个子树中存在的条目数,这有助于查询的并行化。LSM 使我们能够将更新表的过程与查询服务机制分离开来,因为实时查询针对的是不同版本的数据,一旦下一批摄取(称为增量)已完全准备好进行查询,这些数据就会自动更新。
分割问题
在我们的上下文中,数据分区问题是,我们有一张非常大的表,以 LSM 树表示。在下图中,Delta 1 和 2 各自有自己的 B 树,总共代表 70 条记录。Napa 将记录分成两部分,并将每部分分配给不同的机器。该问题变成了树林的分区问题,需要一种可以快速将树分成两个相等部分的 树遍历算法。
为了避免访问树的所有节点,我们引入了“足够好”分区的概念。当我们开始将树切割和分区成两部分时,我们会估计如果在那一刻终止分区过程,当前答案会有多糟糕。这是我们距离答案有多近的标准,下面用总误差幅度 40 表示(在执行的这个点,预计两部分的大小在 15 到 35 条记录之间,不确定性加起来为 40)。每个后续遍历步骤都会降低误差估计,如果两部分大致相等,则停止分区过程。此过程持续到达到所需的误差幅度,此时我们可以保证两部分大致相等。
渐进式分割算法
渐进式分区包含“足够好”的概念,即它采取一系列措施来降低误差估计。输入是一组 B 树,目标是将树切成大小大致相等的部分。该算法遍历其中一棵树(图中为“向下钻取”),从而降低误差估计。该算法由存储在树的每个节点中的统计数据引导,以便它在每一步都做出明智的动作。这里的挑战是决定如何以最佳方式引导努力,以便以尽可能少的步骤快速降低误差界限。渐进式分区有利于我们的用例,因为算法运行的时间越长,各部分就越相等。这也意味着,如果算法在任何时候停止,仍然可以获得良好的分区,其中质量与花费的时间相对应。
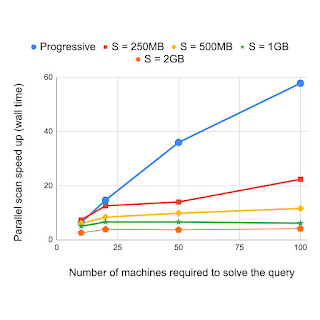
该领域的先前工作使用采样表来驱动分区过程,而 Napa 方法使用 B 树。如前所述,即使只是来自 PB 级表的样本,其数据也可能非常庞大。基于树的分区方法可以比基于样本的方法更有效地实现分区,因为基于样本的方法不使用采样记录的树形组织。我们将渐进式分区与替代方法进行了比较,其中以各种分辨率对表进行采样(例如,每 250 MB 采样 1 条记录等)有助于对查询进行分区。实验结果表明,对于需要不同数量机器的查询,渐进式分区可以相对加快速度。这些结果表明,渐进式分区比现有方法快得多,并且速度随着查询规模的增加而增加。
结论
Napa 的渐进式分区算法可有效优化数据库查询,使 Google Ads 每天能够处理数十亿次客户报告查询。我们注意到,树遍历是计算机科学入门课程学生常用的一种技术,但它也是 Google 的一个关键用例。我们希望本文能够激励我们的读者,因为它展示了简单的技术和精心设计的数据结构如果使用得当,可以发挥巨大的作用。查看论文和最近介绍Napa 的演讲以了解更多信息。
致谢
这篇博文介绍了 Junichi Tatemura、Tao Zou、Jagan Sankaranarayanan、Yanlai Huang、Jim Chen、Yupu Zhu、Kevin Lai、Hao Zhu、Gokul Nath Babu Manoharan、Goetz Graefe、Divyakant Agrawal、Brad Adelberg、Shilpa Kolhar 和 Indrajit 之间的合作成果罗伊.
评论