很多对语法有疑问的人都会向 Google 搜索寻求指导。虽然现有功能(例如“您的意思是”)已经可以处理简单的拼写错误更正,但更复杂的语法错误更正 (GEC) 超出了它们的范围。开发新的 Google 搜索功能之所以具有挑战性,是因为它们必须具有较高的准确率和召回率,同时快速输出结果。
处理 GEC 的传统方法是将其视为翻译问题,并使用自回归Transformer模型逐个解码响应,并以先前生成的标记为条件。然而,尽管 Transformer 模型已被证明在 GEC 中是有效的,但它们并不是特别高效,因为由于自回归解码,生成无法并行化。通常,只需进行少量修改即可使输入文本在语法上正确,因此另一种可能的解决方案是将 GEC 视为文本编辑问题。如果我们可以运行自回归解码器仅生成修改,那么这将大大降低 GEC 模型的延迟。
为此,我们在EMNLP 2022成果发布会上发表的“ EdiT5:使用 T5 Warm-Start 进行半自回归文本编辑”中描述了一种基于T5 Transformer 编码器-解码器架构的新型文本编辑模型。EdiT5 为 Google 搜索语法检查功能提供支持,该功能可让您检查短语或句子的语法是否正确,并在需要时提供更正。当搜索查询中包含短语“语法检查”且底层模型对更正有信心时,语法检查就会显示出来。此外,当搜索理解到这是可能的意图时,它会显示某些不包含“语法检查”短语的查询。
模型架构
对于 Google 的低延迟应用程序,Transformer 模型通常在TPU上运行。由于其快速矩阵乘法单元 (MMU),这些设备针对快速执行大型矩阵乘法进行了优化,例如在短短几毫秒内对数百个 token 运行 Transformer 编码器。相比之下,Transformer 解码对 TPU 功能的利用率很低,因为它迫使它一次只处理一个 token。这使得自回归解码成为基于翻译的 GEC 模型中最耗时的部分。
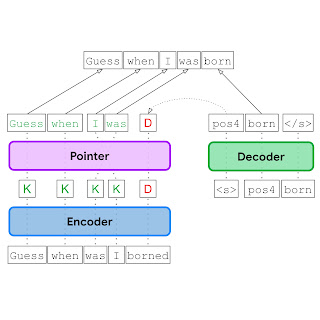
在 EdiT5 方法中,我们将 GEC 视为文本编辑问题,从而减少了解码步骤的数量。EdiT5 文本编辑模型基于T5 Transformer 编码器-解码器架构,并进行了一些关键修改。给定一个带有语法错误的输入,EdiT5 模型使用编码器来确定要保留或删除哪些输入标记。保留的输入标记形成草稿输出,可选择使用非自回归指针网络对其进行重新排序。最后,解码器输出草稿中缺失的标记,并使用指向机制来指示应将每个新标记放在何处以生成语法正确的输出。解码器仅运行以生成草稿中缺失的标记,因此,运行的步骤比 GEC 翻译方法所需的步骤少得多。
为了进一步降低解码器延迟,我们将解码器缩减为单层,并通过增加编码器的大小进行补偿。总体而言,这显著降低了延迟,因为编码器中的额外工作可以高效并行化。
给定一个带有语法错误的输入(“猜猜我是什么时候出生的”),EdiT5 模型使用编码器来确定要保留(K)或删除(D)哪些输入标记,使用指针网络(指针)对保留的标记进行重新排序,并使用解码器插入生成语法正确的输出所需的任何新标记。
我们将 EdiT5 模型应用于公共 BEA 语法错误更正基准,比较了不同的模型大小。实验结果表明,具有 391M 个参数的 EdiT5 大型模型可获得更高的F0.5 分数(用于衡量更正的准确性),同时与具有 248M 个参数的 T5 基础模型相比,其速度提高了 9 倍。EdiT5 模型的平均延迟仅为 4.1 毫秒。
不同尺寸的 T5 和 EdiT5 模型在公共 BEA GEC 基准上的性能与平均延迟的关系图。与 T5 相比,EdiT5 提供了更好的延迟-F0.5 权衡。请注意,x 轴是对数的。
利用大型语言模型改进训练数据
我们之前的研究以及上述结果表明,模型大小在生成准确的语法更正方面起着至关重要的作用。为了结合大型语言模型 (LLM) 的优势和 EdiT5 的低延迟,我们利用了一种称为硬蒸馏的技术。首先,我们使用与Gboard 语法模型类似的数据集训练教师 LLM 。然后使用教师模型为学生 EdiT5 模型生成训练数据。
语法模型的训练集由不符合语法的源句/符合语法的目标句对组成。一些训练集的目标句含有噪声,包括语法错误、不必要的释义或不必要的伪像。因此,我们使用教师模型生成新的伪目标,以获得更干净、更一致的训练数据。然后,我们使用一种称为自我训练的技术,用伪目标重新训练教师模型。最后,我们发现,当源句包含许多错误时,教师有时只会纠正部分错误。因此,我们可以通过第二次将伪目标输入教师 LLM 来进一步提高伪目标的质量,这种技术称为迭代细化。
训练大型教师模型进行语法错误纠正 (GEC) 的步骤。自我训练和迭代改进可消除原始目标中出现的不必要的释义、伪像和语法错误。
综合起来
使用改进的 GEC 数据,我们训练了两个基于 EdiT5 的模型:一个语法错误校正模型和一个语法分类器。使用语法检查功能时,我们首先通过校正模型运行查询,然后使用分类器模型检查输出是否确实正确。只有这样,我们才会向用户展示校正结果。
拥有单独分类器模型的原因是为了更轻松地在准确率和召回率之间进行权衡。此外,对于对模型的模糊或无意义的查询,最佳校正尚不明确,分类器可以降低提供错误或令人困惑的校正的风险。
结论
我们基于最先进的 EdiT5 模型架构开发了一种高效的语法校正模型。该模型允许用户通过在查询中包含“语法检查”短语来检查其在 Google 搜索中的查询的语法性。
致谢
我们非常感谢其他团队成员做出的重要贡献,包括 Akash R、Aliaksei Severyn、Harsh Shah、Jonathan Mallinson、Mithun Kumar SR、Samer Hassan、Sebastian Krause 和 Shikhar Thakur。我们还要感谢 Felix Stahlberg、Shankar Kumar 和 Simon Tong 提供的有益讨论和建议。
评论