在为实际应用构建机器学习模型时,我们需要考虑多种模态的输入,以便捕捉周围世界的各个方面。例如,音频、视频和文本都提供了关于视觉输入的多样化和互补的信息。然而,由于模态的异质性,构建多模态模型具有挑战性。一些模态可能在时间上同步得很好(例如音频、视频),但与文本不一致。此外,视频和音频信号中的数据量比文本中的数据量大得多,因此在将它们组合到多模态模型中时,视频和音频通常无法完全使用,需要进行不成比例的压缩。对于较长的视频输入,这个问题会更加严重。
在“ Mirasol3B:一种用于时间对齐和上下文模态的多模态自回归模型”中,我们引入了一种用于跨音频、视频和文本模态进行学习的多模态自回归模型 (Mirasol3B)。主要思想是将多模态建模分解为单独的聚焦自回归模型,根据模态的特征处理输入。我们的模型由一个用于时间同步模态(音频和视频)的自回归组件和一个用于不一定时间对齐但仍是连续的模态(例如文本输入,如标题或描述)的单独自回归组件组成。此外,时间对齐的模态在时间上被划分,其中可以联合学习局部特征。通过这种方式,音频视频输入按时间建模,并分配了比之前研究更多的参数。与其他多模态模型相比,通过这种方法,我们可以毫不费力地处理更长的视频(例如 128-512 帧)。在 3B 参数下,Mirasol3B 与之前的Flamingo (80B) 和PaLI-X (55B) 模型相比更为紧凑。最后,Mirasol3B 在视频问答(video QA)、长视频问答和音频-视频-文本基准测试中的表现优于最先进的方法。
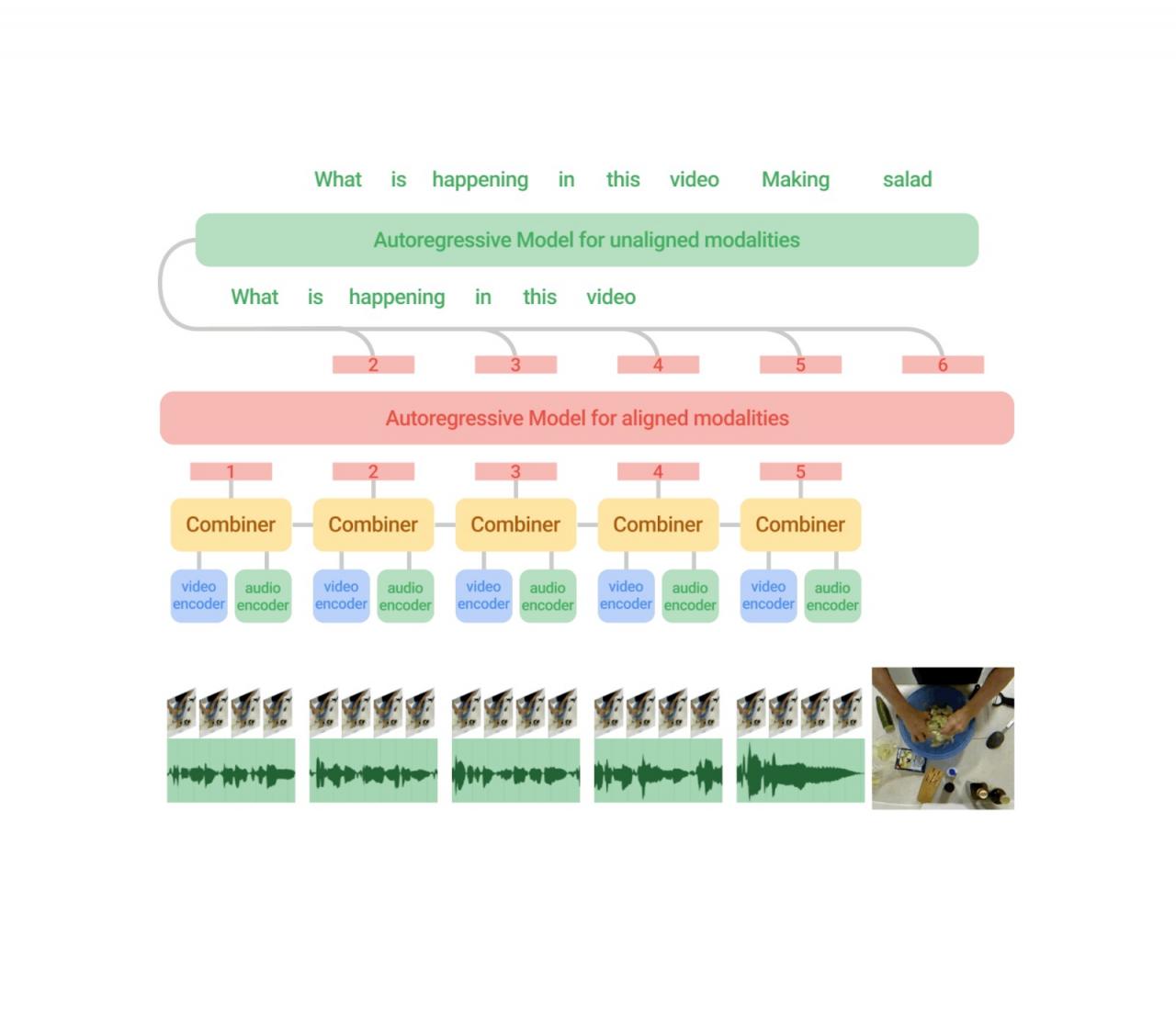
Mirasol3B 架构由一个针对按块划分的时间对齐模态(音频和视频)的自回归模型和一个针对未对齐上下文模态(例如文本)的单独自回归模型组成。联合特征学习由 Combiner 进行,Combiner 学习紧凑但信息量足够的特征,从而可以处理较长的视频/音频输入。
协调时间一致和上下文一致的模式
视频、音频和文本是具有不同特征的不同模态。例如,视频是一种时空视觉信号,每秒 30-100 帧,但由于数据量巨大,当前模型通常只处理每个视频32-64 帧。音频是一种一维时间信号,其频率比视频高得多(例如,16 Hz),而适用于整个视频的文本输入通常是 200-300 个单词序列,并作为音频视频输入的上下文。为此,我们提出了一个模型,该模型由一个自回归组件组成,该组件融合并联合学习时间对齐信号(这些信号以高频率发生且大致同步),另一个自回归组件用于处理非对齐信号。时间对齐和上下文模态组件之间的学习通过交叉注意机制进行协调,该机制允许两者在按顺序学习时交换信息,而无需在时间上同步它们。
视频和音频的时间对齐自回归建模
长视频可以传达丰富的信息和连续发生的活动。然而,目前的模型通过一次性提取所有信息来进行视频建模,而没有足够的时间信息。为了解决这个问题,我们应用了一种自回归建模策略,其中我们根据之前时间间隔的特征表示来调整一个时间间隔的联合学习视频和音频表示。这保留了时间信息。
视频首先被分割成更小的视频块。每个块本身可以是 4-64 帧。然后,每个块对应的特征由一个称为 Combiner(如下所述)的学习模块处理,该模块在当前步骤生成联合音频和视频特征表示 - 此步骤提取并压缩每个块最重要的信息。接下来,我们使用自回归 Transformer 处理这个联合特征表示,它将注意力放在前一个特征表示上,并为下一步生成联合特征表示。因此,该模型不仅学习如何表示每个单独的块,还学习如何表示块在时间上的关系。
我们对音频和视频输入使用自回归建模,按时间对它们进行划分并学习联合特征表示,然后按顺序进行自回归学习。
使用模态组合器对长视频进行建模
为了将每个视频块中的视频和音频信息信号组合起来,我们提出了一个称为组合器的学习模块。通过获取与特定视频时间帧相对应的音频输入,可以对齐视频和音频信号。然后,我们在时空上处理视频和音频输入,提取与输入变化特别相关的信息(对于视频,我们使用稀疏视频管,对于音频,我们应用频谱图表示,两者都由Vision Transformer 处理)。我们将这些特征连接并输入到组合器,组合器旨在学习一种捕获这两个输入的新特征表示。为了应对视频和音频信号中大量数据的挑战,组合器的另一个目标是降低联合视频/音频输入的维数,这可以通过选择要生成的较少数量的输出特征来实现。组合器可以简单地实现为因果变换器,它在时间方向上处理输入,即仅使用前一步或当前步骤的输入。或者,组合器可以具有可学习的记忆,如下所述。
组合器样式
Combiner 的简单版本采用了 Transformer 架构。更具体地说,当前块(以及可选的先前块)的所有音频和视频特征都被输入到 Transformer 并投影到较低的维度,即,选择较少数量的特征作为输出“组合”特征。虽然 Transformer 通常不用于此上下文,但我们发现,如果m是所需的输出维度,则通过选择Transformer 的最后m个输出(如下所示),可以有效地降低输入特征的维度。或者,Combiner 可以具有内存组件。例如,我们使用支持可微分内存单元的Token Turing Machine (TTM),累积和压缩来自所有先前时间步骤的特征。使用固定内存允许模型在每一步使用更紧凑的特征集,而不是处理来自先前步骤的所有特征,从而减少计算量。
我们使用一个简单的基于 Transformer 的组合器(左)和一个基于令牌图灵机(TTM)的记忆组合器(右),它使用内存来压缩特征的先前历史记录。
结果
我们在多个基准测试(MSRVTT-QA、ActivityNet-QA和NeXT-QA)上评估了我们的方法,这些测试针对视频问答任务,即发出有关视频的基于文本的问题,模型需要回答。这评估了模型理解基于文本的问题和视频内容以及形成答案的能力,并且只关注相关信息。在这些基准测试中,后两个针对长视频输入,并提出更复杂的问题。
我们还在更具挑战性的开放式文本生成设置中评估了我们的方法,其中模型以不受约束的方式将答案生成为自由格式的文本,要求与基本事实答案完全匹配。虽然这种更严格的评估将同义词视为不正确,但它可能更好地反映了模型的泛化能力。
我们的结果表明,在大多数基准测试中,包括所有采用开放式生成评估的基准测试中,我们的性能都优于最先进的方法——值得注意的是,我们的模型只有 3B 个参数,比 Flamingo 80B 等先前的方法小得多。我们仅使用视频和文本输入来与其他工作进行比较。重要的是,我们的模型可以处理 512 帧而无需增加模型参数,这对于处理较长的视频至关重要。最后,使用 TTM Combiner,我们看到了更好或相当的性能,同时将计算量减少了 18%。
MSRVTT-QA(视频 QA)数据集上的结果。
NeXT-QA基准测试的结果,该基准测试以长视频为视频 QA 任务提供依据。
音频视频基准测试结果
热门音频视频数据集VGG-Sound和EPIC-SOUNDS的结果如下所示。由于这些基准仅用于分类,我们将它们视为开放式文本生成设置,其中我们的模型生成所需类别的文本;例如,对于与“打鼓”活动相对应的类别 ID,我们预计模型会生成文本“打鼓”。在某些情况下,即使我们的模型在生成开放式设置中输出结果,我们的方法也比之前的最佳方法好很多。
VGG-Sound(音频视频 QA)数据集上的结果。
EPIC-SOUNDS(音频视频 QA)数据集上的结果。
自回归建模的好处
我们进行了一项消融研究,将我们的方法与使用相同输入信息但采用标准方法(即没有自回归和组合器)的一组基线进行比较。我们还比较了预训练的效果。由于标准方法不适合处理较长的视频,因此为了公平比较,此实验仅针对所有设置中的 32 帧和 4 个块进行。我们发现 Mirasol3B 的改进对于相对较短的视频仍然有效。
消融实验比较了我们模型的主要组件。使用组合器、自回归建模和预训练都可以提高性能。
结论
我们提出了一个多模态自回归模型,通过协调时间对齐和时间不对齐模态之间的学习来解决与多模态数据异质性相关的挑战。时间对齐的模态通过组合器进一步随时间自回归处理,控制序列长度并产生强大的表示。我们证明,一个相对较小的模型可以成功表示长视频并有效地与其他模态结合。在视频和音频视频问答方面,我们的表现优于最先进的方法(包括一些更大的模型)。
致谢
本研究由 AJ Piergiovanni、Isaac Noble、Dahun Kim、Michael Ryoo、Victor Gomes 和 Anelia Angelova 共同撰写。我们感谢 Claire Cui、Tania Bedrax-Weiss、Abhijit Ogale、Yunhsuan Sung、Ching-Chung Chang、Marvin Ritter、Kristina Toutanova、Ming-Wei Chang、Ashish Thapliyal、Xiyang Luo、Weicheng Kuo、Aren Jansen、Bryan Seybold、Ibrahim Alabdulmohsin、Jialin Wu、Luke Friedman、Trevor Walker、Keerthana Gopalakrishnan、Jason Baldridge、Radu Soricut、Mojtaba Seyedhosseini、Alexander D'Amour、Oliver Wang、Paul Natsev、Tom Duerig、Younghui Wu、Slav Petrov 和 Zoubin Ghahramani 的帮助和支持。我们还要感谢 Tom Small 制作动画。
评论