我们为文本转语音 (TTS) 系统提出了一种新的零样本语音传输模块,可以恢复患有构音障碍、失去或从未有过典型声音的患者的声音。
声音特征对个人身份的构建和认知有重大影响。因身体或神经系统疾病导致失声,会给人带来深刻的失落感,打击一个人身份的核心。患有退行性神经疾病(如肌萎缩侧索硬化症 (ALS)、帕金森症和多发性硬化症)的人,其声音的一些独特特征可能会随着时间的推移而退化。有些人天生患有肌肉萎缩症等疾病,这些疾病会影响发音系统并限制他们发出某些声音的能力。由于缺乏听觉输入和反馈,严重的耳聋也会影响发声和发音模式。这些疾病会给人们带来终生的挑战,使他们无法与人们普遍听到的典型语音保持一致。
近年来,语音转换 (VT) 技术取得了新进展,并融入了文本转语音 (TTS)、语音转换 (VC) 和语音转语音翻译模型。例如,在我们之前的工作中,我们建立了一个 VC 模型,将非典型语音直接转换为合成的预定典型语音,以便其他人更容易理解。然而,对于许多患有构音障碍的人来说,VT 扩展了语音技术,帮助他们恢复原来的声音,并可能预测他们已经失去的语音模式。
可以使用少样本或零样本训练为给定说话者设计 VT 模块。在少样本训练中,使用给定说话者的语音样本来调整预训练模型以传输或克隆其语音。这种方法通常产生具有高说话者语音保真度的高质量语音,具体取决于训练样本的数量和质量。更具挑战性的方法是零样本,它不需要训练,而是在生成过程中将给定说话者的音频参考样本(例如 10 秒)提供给系统,以将其语音转换为输出合成语音。这些系统的质量差异很大,并且不能保证产生与参考语音高保真的语音。少样本方法对于那些曾经有典型语音并在病因进展(或发生身体伤害)之前存储了一组高质量语音样本的说话者可能有效。另一方面,零样本更适合那些没有存储足够语音样本或从未有过典型声音的构音障碍说话者。此外,零样本系统可以轻松扩展和部署。
在这篇博文中,我们描述了一个零样本 VT 模块,它可以轻松插入到最先进的 TTS 系统中,以恢复输入说话者的声音。当说话者只存储了一小组声音或只有非典型语音可用时,都可以使用它。我们将此模块添加到我们的 TTS系统中,并使用它来恢复存储了典型语音的说话者的声音。我们还表明,即使输入参考语音不典型,同一模型也能产生高质量的语音,并保留高保真语音,这对那些没有存储语音或从未有过典型语音的人来说很有用。最后,我们证明了这样的模块能够跨语言传输语音,即使输入参考语音的语言与目标语言不同。
带有语音转换模块的文本转语音模型
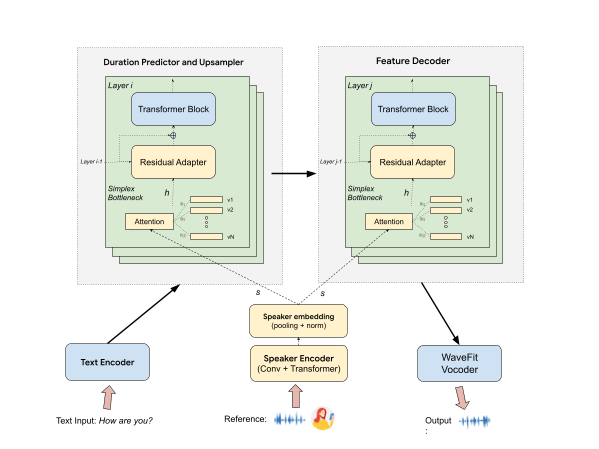
TTS 推理系统由一个文本编码器组成,它将语言信息转换为一系列隐藏表示。然后,这些表示被输入到标记持续时间预测器和上采样器中,后者生成与预测输出持续时间成比例的更长序列。此扩展序列被传递到特征解码器,以生成与合成声学特征相对应的隐藏特征。最后,WaveFit声码器将这些特征转换为输出时域波形。
我们的新 VT 模块是此 TTS 系统的扩展,它以参考语音示例为输入。此扩展使 TTS 模型能够传输参考语音中的语音以生成此语音的合成语音。此扩展在下图中的黄色组件中显示。VT 模块由扬声器编码器、瓶颈模块和残差适配器组成。
0ShotVT-1a
带语音传输的TTS模型架构。
VT 说话人编码器从 2 至 14 秒的参考语音中获取频谱图。它提取高级表示,将输入参考语音的声学语音和韵律特征总结为嵌入向量。然后,此向量被传递到持续时间和特征解码器的所有层。
在每一层中,我们添加一个 1024 维单纯形瓶颈层(基于全局样式标记),以将嵌入向量约束在单纯形内。此层还有助于确保嵌入空间的连续性和完整性。单纯形本身可以在训练过程中学习。我们发现,这种瓶颈选择对于为未见过的声音建模零样本能力至关重要,尤其是对于说话方式不典型的说话者。
最后,瓶颈层的输出与前一层的输出连接起来,并提供给在每两个连续层之间添加的残差适配器。使用残差适配器使模型模块化 - 即,可以将这个 VT 模块插入和拔出预训练的TTS 模型,而不会影响原始 TTS 模型的质量。此外,它们使我们能够调整和专用一组非常小的参数来执行少量训练,以便在启用语音库时完善目标语音。鉴于这些适配器具有参数高效的特性,因此可以按需加载。
模型训练
我们遵循先前定义的程序,使用多语言训练数据来获得包含 VT 扩展的多语言 TTS 系统。由于模型现在接受文本和参考语音,我们在每个训练样本中传递目标语音中的随机连续块(2-14 秒)作为参考。使用随机块有助于防止时长和语言信息的泄露。回想一下,由于模型是在多语言数据上训练的,因此 VT 模块是多语言的。
实验
典型语音样本
以下是使用典型参考语音的零样本示例,用于演示在发生任何语音质量下降之前录制说话者的声音。我们使用VCTK语料库中的样本演示了零样本能力的概念(我们的GitHub 存储库上的完整音频样本列表):
我们还使用来自 VCTK 语料库的参考说话者,使用英语和六种语言的典型参考语音测试了 TTS 零样本模型的跨语言能力。转录文本及其翻译是使用 Gemini 自动生成的。
我们进行了另一组跨语言主观评估,发现平均有 73.1% (± 4.7) 的人工评分者认为给定的英语参考和自动翻译的合成话语中的说话者是同一个人。我们所有的评分者都是相应测试语言的母语人士。我们还报告了每种语言的平均意见分数 ( MOS;从 1 到 5),以衡量我们的 TTS 系统输出音频的自然度和质量。
语音传输问题
我们认识到,在语音传输技术中,合成语音被滥用的可能性越来越令人担忧。为了解决这个问题,我们使用音频水印来嵌入水印,以便能够检测到我们模型中的合成语音。该技术涉及在合成音频波形中嵌入不可察觉的信息。可以使用专门的软件检测这些隐藏的数据,从而识别可能被操纵或滥用的音频内容。值得注意的是,对于从未有过典型语音模式的人来说,滥用的风险要低得多。在这种情况下,输出的合成性质将显而易见,从而最大限度地降低了欺骗的可能性。
致谢
我们要感谢 Aubrie Lee、Dimitri Kanevsky、 Kyle Kastner、Isaac Elias、Gary Wang、Andrew Rosenberg、Takaaki Saeki、Yuma Koizumi、Bhuvana Ramabhadran、Françoise Beaufays、RJ Skerry-Ryan、Ron Weiss、Zoe Ortiz 以及 Google 语音团队的其他成员对此项目的有益反馈和贡献。
评论