滑铁卢大学的一组研究人员开发出了一种新的机器学习方法,可以 88% 的准确率检测社交媒体平台上的仇恨言论,让员工免于数百小时的情感伤害工作。
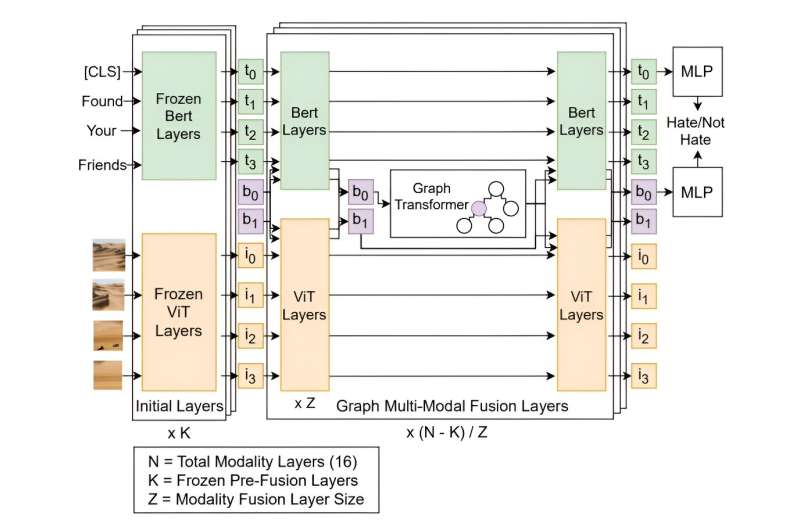
这种方法被称为多模态讨论转换器 (mDT),与以前的仇恨言论检测方法不同,它可以理解文本和图像之间的关系,并将评论置于更大的上下文中。这对于减少误报特别有用,误报通常会因文化敏感性语言而被错误地标记为仇恨言论。
“我们真心希望这项技术能够帮助减少人工筛选仇恨言论所带来的情感成本,”滑铁卢大学计算机科学博士生、这项研究的第一作者 Liam Hebert 说道。“我们相信,通过在人工智能应用中采取以社区为中心的方法,我们可以帮助为所有人创造更安全的网络空间。”
多年来,研究人员一直在构建模型来分析人类对话的含义,但这些模型在理解细微的对话或上下文陈述方面一直存在困难。之前的模型识别仇恨言论的准确率仅为 74%,低于滑铁卢研究的准确率。
“理解仇恨言论时,语境非常重要,”赫伯特说。“例如,‘太恶心了!’这句话本身可能无伤大雅,但如果它是针对一张菠萝披萨的照片,或者针对一个边缘群体的人,那么它的含义就会发生巨大变化。
“理解这种区别对于人类来说很容易,但训练模型来理解讨论中的上下文联系,包括考虑其中的图像和其他多媒体元素,实际上是一个非常困难的问题。”
与之前的研究不同,滑铁卢团队在数据集上构建和训练了他们的模型,该数据集不仅包含孤立的仇恨评论,还包含这些评论的背景。该模型在 8,266 个 Reddit 讨论中进行了训练,其中包含来自 850 个社区的 18,359 条带标签的评论。
“每天有超过 30 亿人使用社交媒体,”赫伯特说。“这些社交媒体平台的影响力已达到前所未有的水平。我们迫切需要大规模地检测仇恨言论,以建立人人受尊重、安全的空间。”
本站全部资讯来源于实验室原创、合作机构投稿及网友汇集投稿,仅代表个人观点,不作为任何依据,转载联系作者并注明出处:https://www.lvsky.net/290.html
评论