随着机器学习 (ML) 领域近年来的快速发展,机器可以理解自然语言、参与对话、绘制图像、制作视频等。现代 ML 模型使用 ML 编程框架进行编程和训练,例如TensorFlow、JAX、PyTorch等。这些库为 ML 从业者提供高级指令,例如线性代数运算(例如矩阵乘法、卷积等)和神经网络层(例如2D 卷积层、Transformer 层)。重要的是,从业者不必担心如何让他们的模型在硬件上高效运行,因为 ML 框架将通过底层编译器自动优化用户的模型。因此,ML 工作负载的效率取决于编译器的性能。编译器通常依靠启发式方法来解决复杂的优化问题,但通常导致性能不理想。
在这篇博文中,我们介绍了机器学习在机器学习方面的令人兴奋的进步。特别是,我们展示了如何使用机器学习来提高机器学习工作负载的效率!先前的内部和外部研究都表明,我们可以通过选择更好的机器学习编译器决策来使用机器学习来提高机器学习程序的性能。尽管存在一些用于程序性能预测的数据集,但它们针对的是小型子程序,例如基本块或内核。我们推出了“ TpuGraphs:大型张量计算图上的性能预测数据集”(在NeurIPS 2023上展示),我们最近发布了它以推动机器学习在程序优化方面的更多研究。我们在该数据集上举办了一场Kaggle 竞赛,最近有来自 66 个国家/地区的 616 支队伍的 792 名参与者参加。此外,在“通过图段训练学习大型图属性预测”中,我们介绍了一种扩展图神经网络(GNN) 训练以处理以图表示的大型程序的新方法。该技术既可以在内存容量有限的设备上训练任意大的图形,又可以提高模型的泛化能力。
机器学习编译器
ML 编译器是将用户编写的程序(这里指 TensorFlow 等库提供的数学指令)转换为可执行文件(在实际硬件上执行的指令)的软件例程。ML 程序可以表示为计算图,其中节点表示张量运算(例如矩阵乘法),边表示从一个节点流向另一个节点的张量。ML 编译器必须解决许多复杂的优化问题,包括图级和内核级优化。图级优化需要整个图的上下文来做出最佳决策并相应地转换整个图。内核级优化一次转换一个内核(融合子图),独立于其他内核。
ML 编译器中的重要优化包括图级优化和内核级优化。
为了提供一个具体的例子,想象一个矩阵(二维张量):
它可以以 [ABC abc] 或 [A a B b C c] 的形式存储在计算机内存中,分别称为行主内存布局和列主内存布局。一项重要的 ML 编译器优化是为程序中的所有中间张量分配内存布局。下图显示了同一程序的两种不同布局配置。让我们假设在左侧,分配的布局(红色)是每个单独运算符的最有效选项。但是,此布局配置要求编译器插入复制操作以在加法和卷积运算之间转换内存布局。另一方面,右侧配置对于每个单独的运算符来说可能效率较低,但它不需要额外的内存转换。布局分配优化必须在局部计算效率和布局转换开销之间进行权衡。
节点表示张量算子,用其输出张量形状 [ n 0 , n 1 , ...] 注释,其中n i是维度i的大小。布局 { d 0 , d 1 , ...} 表示内存中的从小到大的顺序。应用的配置以红色突出显示,其他有效配置以蓝色突出显示。布局配置指定有影响的算子(即卷积和重塑)的输入和输出的布局。当布局不匹配时,会插入复制算子。
如果编译器做出最佳选择,则可以显著提高速度。例如,我们在XLA基准测试套件中选择最佳布局配置时,速度比默认编译器配置快 32%。
TpuGraphs 数据集
鉴于上述情况,我们的目标是通过改进 ML 编译器来提高 ML 模型的效率。具体来说,为编译器配备 一个学习成本模型 会非常有效,该模型接收输入程序和编译器配置,然后输出程序的预测运行时间。
基于此,我们发布了 TpuGraphs,这是一个用于学习在 Google 定制张量处理单元(TPU) 上运行的程序的成本模型的数据集。该数据集针对两种 XLA 编译器配置:布局(行主序和列主序的泛化,从矩阵到更高维张量)和平铺(平铺大小的配置)。我们在TpuGraphs GitHub上提供了下载说明和入门代码。数据集中的每个示例都包含一个 ML 工作负载的计算图、一个编译配置以及使用该配置编译时图的执行时间。数据集中的图是从开源 ML 程序中收集的,具有流行的模型架构,例如ResNet、EfficientNet、Mask R-CNN和Transformer。该数据集提供的图比最大的(早期)图属性预测数据集(具有可比的图大小)多 25 倍,与现有的 ML 程序性能预测数据集相比,图大小平均大 770 倍。在这种大大扩展的规模下,我们首次可以探索大图上的图级预测任务,该任务面临着可扩展性、训练效率和模型质量等挑战。
TpuGraphs 的规模与其他图属性预测数据集相比。
我们通过我们的数据集提供基线学习成本模型(架构如下所示)。由于输入程序以图的形式表示,因此我们的基线模型基于 GNN。节点特征(如下方蓝色所示)由两部分组成。第一部分是操作码 id,这是节点的最重要信息,它指示张量操作的类型。因此,我们的基线模型通过嵌入查找表将操作码 id 映射到操作码嵌入。然后将操作码嵌入与第二部分(其余节点特征)连接起来,作为 GNN 的输入。我们结合 GNN 生成的节点嵌入,使用简单的图池化缩减(即总和和平均值)来创建图的固定大小嵌入。然后,前馈层将得到的图嵌入线性转换为最终的标量输出。
由于程序可以自然地表示为图形,因此我们的基线学习成本模型采用 GNN。
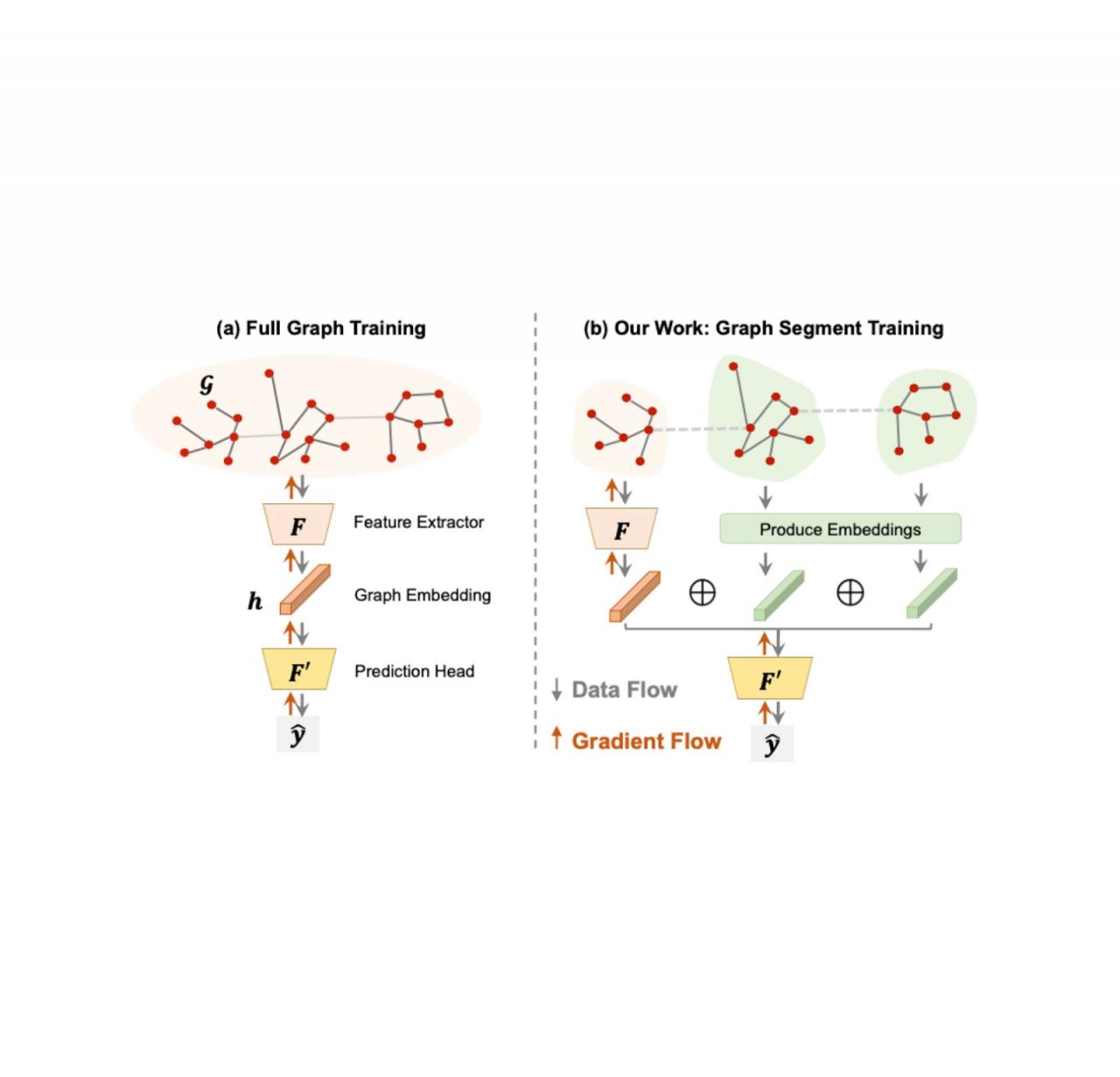
此外,我们提出了图段训练(GST),这是一种扩展 GNN 训练的方法,用于在内存容量有限的设备上处理大型图,当预测任务是针对整个图(即图级预测)时。与节点或边缘级预测的扩展训练不同,图级预测的扩展研究不足,但对我们的领域至关重要,因为计算图可以包含数十万个节点。在典型的 GNN 训练(“全图训练”,下图左侧)中,GNN 模型使用整个图进行训练,这意味着图的所有节点和边缘都用于计算梯度。对于大型图,这在计算上可能是不可行的。在 GST 中,每个大型图被划分为较小的段,并选择随机的段子集来更新模型;生成剩余段的嵌入时不会保存它们的中间激活(以避免消耗内存)。然后组合所有段的嵌入以生成原始大型图的嵌入,然后将其用于预测。此外,我们引入了历史嵌入表,以高效获取图段的嵌入,并引入了段丢弃功能,以缓解历史嵌入带来的陈旧性。总之,我们的完整方法将端到端训练时间加快了 3 倍。
比较全图训练(典型方法)与图段训练(我们提出的方法)。
Kaggle 竞赛
最后,我们在 TpuGraph 数据集上进行了“快还是慢?预测 AI 模型运行时”竞赛。本次竞赛共有来自 616 支队伍的 792 名参赛者参加。我们收到了来自 66 个国家/地区的 10507 份参赛作品。对于 153 名用户(包括前 100 名中的 47 名)来说,这是他们的第一次参赛。我们了解到参赛队伍采用的许多有趣的新技术,例如:
图修剪/压缩:许多团队没有使用 GST 方法,而是尝试了不同的方法来压缩大图(例如,只保留包含可配置节点及其直接邻居的子图)。
特征填充值:一些团队观察到默认填充值 0 是有问题的,因为 0 与有效特征值冲突,因此使用填充值 -1 可以显著提高模型准确率。
节点特征:一些团队观察到额外的节点特征(例如点将军收缩维度)很重要。少数团队发现节点特征的不同编码也很重要。
跨配置注意:获胜团队设计了一个简单的层,允许模型明确地“比较”配置。事实证明,这种技术比让模型单独推断每个配置要好得多。
我们将在 2023 年 12 月 16 日 NeurIPS的系统 ML 研讨会 上的竞赛会议上汇报竞赛情况并预览获胜的解决方案。最后,祝贺所有获奖者,并感谢你们为推动系统 ML 研究所做的贡献!
NeurIPS 博览会
如果您对结构化数据和人工智能的更多研究感兴趣,我们于 12 月 9 日举办了 NeurIPS Expo 小组讨论“图形学习与人工智能相遇”,其中涵盖了推进学习成本模型等!
致谢
Sami Abu-el-Haija(Google 研究)对这项工作和撰写做出了重大贡献。本文中的研究描述了与许多其他合作者的合作,包括 Mike Burrows、Kaidi Cao、Bahare Fatemi、Jure Leskovec、Charith Mendis、Dustin Zelle 和 Yanqi Zhou。
评论