TimesFM 是一个预测模型,在 1000 亿个真实世界时间点的大型时间序列语料库上进行预训练,在不同领域和粒度的各种公共基准上表现出令人印象深刻的零样本性能。
时间序列预测在零售、金融、制造、医疗保健和自然科学等各个领域都无处不在。例如,在零售用例中,人们观察到提高需求预测准确性可以显著降低库存成本并增加收入。深度学习 (DL) 模型已成为预测丰富、多变量时间序列数据的流行方法,因为它们已被证明在各种设置中表现良好(例如,DL 模型在M5 竞赛中表现良好)。
与此同时,用于自然语言处理 (NLP) 任务(例如翻译、检索增强生成和代码完成)的大型基础语言模型也取得了快速进展。这些模型使用来自各种来源(例如常见爬虫和开源代码)的大量文本数据进行训练,从而能够识别语言中的模式。这使它们成为非常强大的零样本工具;例如,当与检索结合使用时,它们可以回答有关当前事件的问题并总结当前事件。
尽管基于深度学习的预测器的表现远胜于传统方法,并且在降低训练和推理成本方面也取得了进展,但它们仍面临挑战:大多数深度学习架构都需要经过漫长而复杂的训练和验证周期,客户才能在新的时间序列上测试模型。相比之下,时间序列预测的基础模型无需额外训练即可对未见过的时间序列数据提供不错的开箱即用预测,从而使用户能够专注于完善实际下游任务(如零售需求计划)的预测。
为此,我们在 ICML 2024 上接受的“仅解码器的时间序列预测基础模型”中引入了TimesFM ,这是一个在包含 1000 亿个真实世界时间点的大型时间序列语料库上进行预训练的单一预测模型。与最新的大型语言模型 (LLM) 相比,TimesFM 要小得多(2 亿个参数),但我们表明,即使在这样的规模下,它在不同领域和时间粒度的各种未见过的数据集上的零样本性能也接近在这些数据集上明确训练的最先进的监督方法。要访问该模型,请访问我们的HuggingFace和GitHub存储库。
用于时间序列预测的仅解码器基础模型
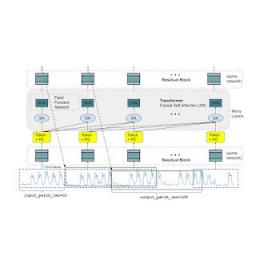
LLM 通常以仅解码器的方式进行训练,涉及三个步骤。首先,将文本分解为称为标记的子词。然后,将标记输入到堆叠的因果转换器层中,这些转换器层产生与每个输入标记相对应的输出(它无法关注未来的标记)。最后,与第 i个标记相对应的输出总结了来自前面标记的所有信息并预测第 ( i +1) 个标记。在推理过程中,LLM 一次生成一个标记的输出。例如,当提示“法国的首都是什么?”时,它可能会生成标记“The”,然后以“法国的首都是什么?The”为条件生成下一个标记“capital”,依此类推,直到生成完整答案:“法国的首都是巴黎”。
时间序列预测的基础模型应该适应可变的上下文(我们观察到的内容)和范围(我们查询模型以预测的内容)长度,同时具有足够的容量来对来自大型预训练数据集的所有模式进行编码。与 LLM 类似,我们使用堆叠的 Transformer 层(自注意力和前馈层)作为 TimesFM 模型的主要构建块。在时间序列预测的背景下,我们将一个补丁(一组连续的时间点)视为最近的长期预测工作所推广的标记。然后,任务是根据堆叠的 Transformer 层末尾的第 i个输出来预测第 ( i +1) 个时间点补丁。
但是,与语言模型相比,它有几个关键的区别。首先,我们需要一个具有残差连接的多层感知器块,将时间序列块转换为可以与位置编码(PE) 一起输入到 Transformer 层的标记。为此,我们使用了与我们之前在长期预测中的工作类似的残差块。其次,在另一端,来自堆叠 Transformer 的输出标记可用于预测比输入块长度更长的后续时间点的长度,即输出块长度可以大于输入块长度。
假设一个长度为 512 个时间点的时间序列用于训练 TimesFM 模型,其中输入块长度为 32,输出块长度为 128。在训练期间,该模型同时训练使用前 32 个时间点预测接下来的 128 个时间点,使用前 64 个时间点预测时间点 65 到 192,使用前 96 个时间点预测时间点 97 到 224,依此类推。在推理期间,假设为模型提供了一个长度为 256 的新时间序列,并负责预测未来的接下来的 256 个时间点。该模型将首先生成时间点 257 至 384 的未来预测,然后以初始长度 256 的输入加上生成的输出为条件,生成时间点 385 至 512。另一方面,如果在我们的模型中,输出补丁长度等于输入补丁长度 32,那么对于相同的任务,我们将不得不经历八个生成步骤,而不仅仅是上面的两个。这增加了更多错误累积的可能性,因此,在实践中,我们看到更长的输出补丁长度可以为长期预测带来更好的性能
TimesFM 架构。
预训练数据
就像 LLM 会随着 token 数量的增加而变得更好一样,TimesFM 需要大量合法的时间序列数据来学习和改进。我们花了大量时间来创建和评估我们的训练数据集,以下是我们发现最有效的数据集:
合成数据有助于基本知识。可以使用统计模型或物理模拟生成有意义的合成时间序列数据。这些基本的时间模式可以教会模型时间序列预测的语法。
真实世界的数据增添了真实世界的韵味。我们梳理了可用的公共时间序列数据集,并有选择地整合了 1000 亿个时间点的大型语料库。这些数据集包括Google Trends和Wikipedia Pageviews,它们跟踪人们感兴趣的内容,并很好地反映了许多其他真实世界时间序列中的趋势和模式。这有助于 TimesFM 了解更大的图景,并在提供训练期间未见过的特定领域上下文时更好地概括。
零样本评估结果
我们使用流行的时间序列基准对训练期间未见过的数据进行了 TimesFM 零样本测试。我们观察到 TimesFM 的表现优于大多数统计方法(如ARIMA、ETS) ,并且可以匹敌或超越在目标时间序列上明确训练过的强大DL 模型(如DeepAR、PatchTST)。
我们使用Monash Forecasting Archive来评估 TimesFM 的开箱即用性能。该档案包含来自交通、天气和需求预测等各个领域的数万个时间序列,涵盖从几分钟到一年的数据的频率。根据现有文献,我们检查了适当缩放的平均绝对误差(MAE) ,以便可以对数据集进行平均。我们发现零样本 (ZS) TimesFM 比大多数监督方法(包括最近的深度学习模型)都要好。我们还使用llmtime(ZS)提出的特定提示技术将TimesFM 与GPT-3.5进行比较,以进行预测。我们证明,尽管 TimesFM 比 llmtime(ZS) 小几个数量级,但其性能却更好。
在莫纳什数据集上,TimesFM(ZS) 与其他监督方法和零样本方法的缩放 MAE(越低越好)的几何平均值(GM,以及我们这样做的原因)。
大多数莫纳什数据集都是短期或中期预测,即预测长度不太长。我们还在流行的长期预测基准上测试了 TimesFM,并与最近最先进的基线PatchTST(和其他长期预测基线)进行了比较。在下图中,我们绘制了ETT数据集上的 MAE,以预测未来的 96 和 192 个时间点。该指标是在每个数据集的最后一个测试窗口上计算的(如llmtime论文所做的那样)。我们看到 TimesFM 不仅超越了 llmtime(ZS) 的性能,而且还与在相应数据集上明确训练的监督 PatchTST 模型的性能相匹配。
TimesFM(ZS) 与 llmtime(ZS) 和 ETT 数据集上的长期预测基线的最后一个窗口 MAE(越低越好)。
结论
我们使用包含 1000 亿个真实世界时间点的大型预训练语料库训练仅使用解码器的基础模型,用于时间序列预测,其中大部分是来自 Google Trends 的搜索兴趣时间序列数据和来自 Wikipedia 的页面浏览量。我们表明,即使是使用我们的 TimesFM 架构的相对较小的 200M 参数预训练模型,也会在来自不同领域和粒度的各种公共基准上表现出令人印象深刻的零样本性能。
致谢
这项工作是 Google Research 和 Google Cloud 的多位个人合作的成果,包括(按字母顺序排列):Abhimanyu Das、Weihao Kong、Andrew Leach、Mike Lawrence、Alex Martin、Rajat Sen、Yang Yang、Skander Hannachi、Ivan Kuznetsov 和 Yichen Zhou。
评论