我们概述了一个社交学习框架,其中 LLM 使用自然语言以隐私意识的方式相互分享知识。我们评估了该框架在各种数据集上的有效性,并提出了在此设置中衡量隐私的定量方法。
大型语言模型 (LLM) 显著提高了解决使用自然语言指定任务的最新水平,通常可以达到接近人类的表现。随着这些模型越来越多地支持辅助代理,它们可以有效地相互学习,就像人们在社交环境中所做的那样,这将使基于 LLM 的代理能够提高彼此的表现。
为了讨论人类的学习过程,班杜拉和沃尔特斯于 1977 年提出了社会学习的概念,概述了人们使用的不同观察学习模型。向他人学习的一种常见方法是通过口头指导(例如来自老师的指导)来描述如何参与特定行为。或者,学习可以通过模仿行为的活生生的例子通过活生生的模型进行。
鉴于 LLM 模仿人类交流的成功,我们在论文“社交学习:面向大型语言模型的协作学习”中研究了 LLM 是否能够使用社交学习相互学习。为此,我们概述了一个社交学习框架,其中 LLM 使用自然语言以隐私感知的方式相互共享知识。我们在各种数据集上评估了我们的框架的有效性,并提出了在此设置下衡量隐私的定量方法。与以前的协作学习方法(例如通常依赖梯度的常见联邦学习方法)不同,在我们的框架中,代理纯粹使用自然语言相互教学。
法学硕士的社会学习
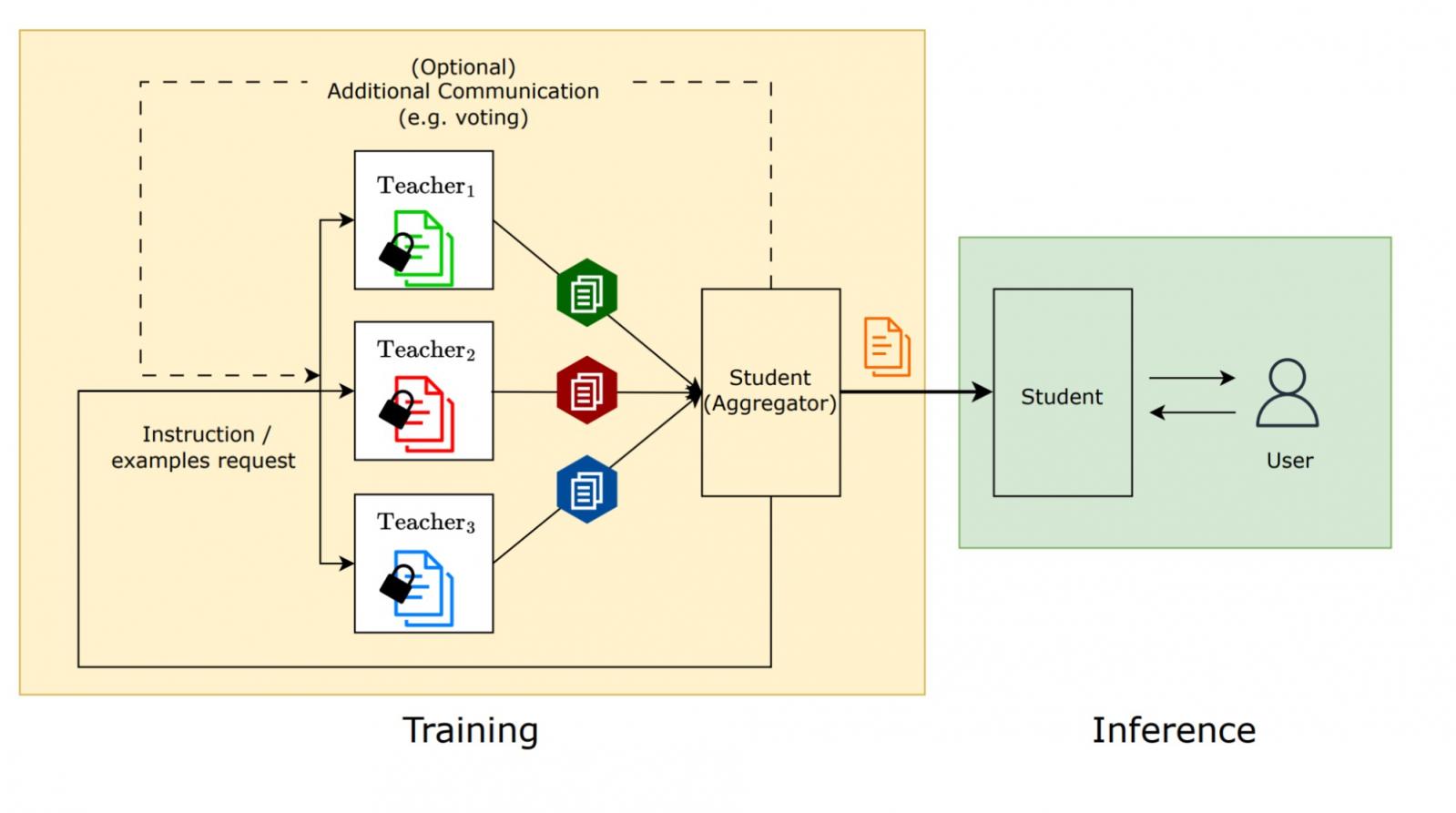
为了将社交学习扩展到语言模型,我们考虑了这样一种场景:LLM 学生应该从已经知道该任务的多个教师实体那里学习解决该任务。在我们的论文中,我们评估了学生在各种任务上的表现,例如短信 (SMS) 中的垃圾邮件检测、解决小学数学问题以及根据给定的文本回答问题。
社会学习过程的可视化:教师模型向学生模型提供指导或少量示例,但不共享其私人数据。
语言模型已经展现出在仅给出少量示例的情况下执行任务的非凡能力——这一过程称为少样本学习。考虑到这一点,我们提供了人工标记的任务示例,使教师模型能够将其教给学生。社交学习的主要用例之一是,由于隐私问题等原因,这些示例无法直接与学生分享。
为了说明这一点,我们来看一个垃圾邮件检测任务的假设示例。教师模型位于设备上,一些用户自愿将收到的来信标记为“垃圾邮件”或“非垃圾邮件”。这些数据很有用,可以帮助训练学生模型区分垃圾邮件和非垃圾邮件,但与其他用户分享私人消息会侵犯隐私,应避免这样做。为了防止这种情况,社交学习过程可以将知识从教师模型转移到学生模型,这样它就可以了解垃圾邮件是什么样子,而无需分享用户的个人短信。
我们通过类比上文讨论的已建立的人类社会学习理论来研究这种社会学习方法的有效性。在这些实验中,我们对教师和学生都使用了PaLM 2-S模型。
社会学习的系统观
社会学习的系统观:在训练时,多个老师教学生。在推理时,学生使用从老师那里学到的知识。
合成示例
与传统社交学习中描述的现场教学模式相对应,我们提出了一种学习方法,即教师为任务生成新的合成示例并将其与学生分享。这样做的动机是,人们可以创建一个与原始示例有足够不同但同样具有教育意义的新示例。事实上,我们观察到,我们生成的示例与真实示例有足够不同的差异,可以保护隐私,同时仍能实现与使用原始示例相当的性能。
社会学习表现 - 1
生成的 8 个示例在多个任务中的表现与原始数据一样好(参见我们的论文)。
我们评估了通过任务套件上的合成示例进行学习的效果。尤其是当示例数量足够高时(例如 n = 16),我们观察到对于大多数任务,共享原始数据和通过社交学习使用合成数据进行教学之间没有统计学上的显著差异,这表明隐私改进不必以牺牲模型质量为代价。
社会学习表现 - 2
生成 16 个示例而不是 8 个示例进一步减少了相对于原始示例的性能差距。
唯一的例外是垃圾邮件检测,使用合成数据进行训练的准确率较低。这可能是因为当前模型的训练过程使它们倾向于仅生成非垃圾邮件示例。在本文中,我们还研究了聚合方法,以选择要使用的良好示例子集。
综合教学
鉴于语言模型在遵循指令方面取得了成功,因此,通过让教师为任务生成指令,口头指令模型也可以自然地适应语言模型。我们的实验表明,提供这种生成的指令可以有效地提高零样本提示的性能,达到与使用原始示例的少样本提示相当的准确度。然而,我们确实发现教师模型在某些任务上可能无法提供良好的指令,例如由于输出的格式要求复杂。
对于Lambada、GSM8k和随机插入,提供合成示例比提供生成指令效果更好,而在其他任务中,生成指令的准确率更高。这一观察结果表明,教学模式的选择取决于手头的任务,类似于最有效的教学方法因任务而异。
社会学习表现 - 3
根据任务的不同,生成指令可能比生成新示例更有效。
记住私人例子
我们希望社交学习中的老师在教授学生时不会透露原始数据的具体信息。为了量化此过程泄露信息的可能性,我们使用了Secret Sharer,这是一种流行的量化模型记忆其训练数据的程度的方法,并将其调整为社交学习环境。我们之所以选择这种方法,是因为它之前曾用于评估联邦学习中的记忆能力。
为了将 Secret Sharer 方法应用于社交学习,我们设计了“金丝雀”数据点,以便我们能够具体衡量训练过程记住了多少数据点。这些数据点包含在教师用来生成新示例的数据集中。社交学习过程完成后,我们可以衡量学生对教师使用的秘密数据点的信心程度,与甚至没有与教师共享的类似数据点相比。
在我们的分析中(论文中有详细讨论),我们使用了包含姓名和代码的金丝雀样本。我们的结果表明,学生对老师使用的金丝雀样本的信心只略高一点。相比之下,当原始数据点直接与学生共享时,对包含的金丝雀样本的信心要比对保留集的信心高得多。这支持了以下结论:老师确实使用其数据进行教学,而不是简单地复制它。
结论和后续步骤
我们引入了一个社交学习框架,允许有权访问私有数据的语言模型通过文本通信传递知识,同时保持数据的隐私。在这个框架中,我们将共享示例和共享指令确定为基本模型,并在多个任务上对其进行评估。此外,我们将秘密共享者指标调整到我们的框架中,提出了一种衡量数据泄露的指标。
接下来,我们正在寻找改进教学过程的方法,例如通过添加反馈循环和迭代。此外,我们还想研究将社交学习用于除文本之外的其他模式。
致谢
我们要感谢 Matt Sharifi、Sian Gooding、Lukas Zilka 和 Blaise Aguera y Arcas,他们都是本文的共同作者。此外,我们还要感谢 Victor Cărbune、Zachary Garrett、Tautvydas Misiunas、Sofia Neata 和 John Platt 的反馈,他们的反馈极大地改善了本文。我们还要感谢 Tom Small 制作的动画人物。
评论