我们深入研究了如何最好地将图表表示为文本,以便法学硕士 (LLM) 能够理解它们——我们的调查发现了影响结果的三个主要因素。
想象一下你周围的一切——你的朋友、厨房里的工具,甚至是自行车的零件。它们都以不同的方式连接在一起。在计算机科学中,术语“图”用于描述对象之间的连接。图由节点(对象本身)和边(两个节点之间的连接,表示它们之间的关系)组成。现在图无处不在。互联网本身就是一个由相互连接的网站组成的巨型图。甚至搜索引擎使用的知识也是以类似图的方式组织的。
此外,想想人工智能的显著进步——例如可以在几秒钟内写故事的聊天机器人,甚至是可以解释医疗报告的软件。这一令人兴奋的进步很大程度上要归功于大型语言模型 (LLM)。新的 LLM 技术不断被开发用于不同的用途。
由于图表无处不在且 LLM 技术正在兴起,在ICLR 2024上发表的“像图表一样对话:为大型语言模型编码图表”中,我们提出了一种方法来教强大的 LLM 如何更好地使用图表信息进行推理。图表是一种有用的信息组织方式,但 LLM 大多是在常规文本上进行训练的。目标是测试不同的技术,看看哪种方法最有效并获得实用的见解。将图表转换成 LLM 可以理解的文本是一项非常复杂的任务。困难源于具有多个节点的图表结构固有的复杂性以及连接它们的错综复杂的边网。我们的工作研究如何将图表转换成 LLM 可以理解的格式。我们还设计了一个名为 GraphQA 的基准来研究不同图表推理问题的不同方法,并展示如何以一种让 LLM 能够解决图表问题的方式来表述与图表相关的问题。我们表明,LLM 在图论推理任务上的表现在三个基本层面上有所不同:1) 图论编码方法,2) 图论任务本身的性质,以及 3) 有趣的是,所考虑的图论结构。这些发现为我们提供了如何为 LLM 最好地表示图论的线索。选择正确的方法可以使 LLM 在图论任务上的表现提高 60%!
TalkGraph1-流程
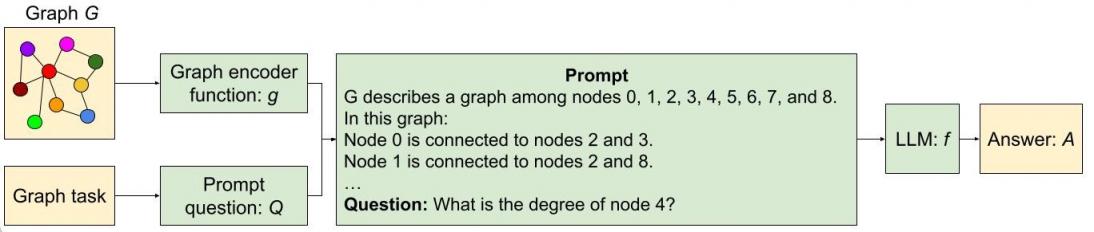
图中显示了使用两种不同的方法将图形编码为文本并将文本和有关图形的问题提供给 LLM 的过程。
图表作为文本
为了能够系统地找出将图表转换为文本的最佳方法,我们首先设计了一个名为GraphQA的基准。将 GraphQA 视为旨在评估强大的 LLM 在图表特定问题上的表现的考试。我们想看看 LLM 能多好地理解和解决涉及不同设置中的图表的问题。为了为 LLM 创建全面而切合实际的考试,我们不仅仅使用一种图表,而是使用多种图表以确保连接数量的广度。这主要是因为不同的图表类型会使解决这些问题变得更容易或更难。通过这种方式,GraphQA 可以帮助揭示 LLM 对图表的看法中的偏见,整个考试更接近 LLM 在现实世界中可能遇到的实际设置。
TalkGraph2-OvervieHero
使用 LLM 进行图形推理的框架概述。
GraphQA 专注于与图相关的简单任务,例如检查边是否存在、计算节点或边的数量、查找连接到特定节点的节点以及检查图中的循环。这些任务看似基础,但却需要理解节点和边之间的关系。通过涵盖从识别模式到创建新连接等不同类型的挑战,GraphQA 可帮助模型学习如何有效地分析图。这些基本任务对于更复杂的图推理至关重要,例如找到节点之间的最短路径、检测社区或识别有影响力的节点。此外,GraphQA 还包括使用各种算法(如Erdős-Rényi、无标度网络、Barabasi-Albert 模型和随机块模型)生成随机图,以及更简单的图结构(如路径、完全图和星形图),从而为训练提供多样化的数据集。
在处理图表时,我们还需要找到提出 LLM 能够理解的与图表相关的问题的方法。提示启发式方法是实现此目的的不同策略。让我们分解一下常见的提示启发式方法:
零样本:简单描述任务(“这个图中是否有循环?”)并告诉 LLM 去做。没有提供示例。
Few-shot:这就像在正式考试之前给 LLM 做一个小练习测试。我们提供了一些示例图表问题及其正确答案。
思路链:在这里,我们通过示例向 LLM 展示如何逐步分解问题。目标是教会它在面对新图表时生成自己的“思维过程”。
零 CoT:与 CoT 类似,但我们不提供训练示例,而是给 LLM 一个简单的提示,例如“让我们一步一步思考”,以触发其自身的问题解决细分。
BAG(构建图表):这是专门针对图表任务的。我们在描述中添加了“让我们构建一个图表...”这句话,帮助 LLM 专注于图表结构。
我们探索了将图表转化为 LLM 可以使用的文本的不同方法。我们的主要问题是:
节点编码:我们如何表示单个节点?测试的选项包括简单整数、常用名称(人物、角色)和字母。
边编码:我们如何描述节点之间的关系?方法包括括号表示法、“是朋友”之类的短语以及箭头之类的符号表示法。
各种节点和边编码被系统地组合起来。这产生了如下图所示的函数:
TalkGraph3-功能
用于通过文本对图形进行编码的图形编码函数的示例。
分析和结果
我们进行了三项关键实验:一项是测试 LLM 如何处理图形任务,另一项是了解 LLM 的大小和不同的图形形状如何影响性能。我们在 GraphQA 上运行所有实验。
LLM 如何处理图形任务
在本次实验中,我们测试了预训练的 LLM 处理图问题(例如识别连接、循环和节点度)的效果。以下是我们了解到的情况:
LLM 很难:在大多数这些基本任务中,LLM 的表现并不比随机猜测好多少。
编码非常重要:我们如何将图形表示为文本对 LLM 性能有很大影响。“事件”编码在大多数任务中都表现出色。
我们的结果总结在下图中。
TalkGraph4-编码器结果
根据不同图形任务的准确率对各种图形编码器函数进行比较。从该图可以得出的主要结论是图形编码函数非常重要。
通常来说越大越好
在这个实验中,我们想看看 LLM 的大小(就参数数量而言)是否会影响它们处理图形问题的能力。为此,我们在 XXS、XS、S 和 L 大小的PaLM 2上测试了相同的图形任务。以下是我们的发现摘要:
总体而言,模型越大,图形推理任务表现越好。额外的参数似乎为它们提供了学习更复杂模式的空间。
奇怪的是,对于“边存在”任务(找出图中的两个节点是否连接)来说,大小并不那么重要。
即使是最大的 LLM 也无法始终击败循环检查问题(确定图表是否包含循环)的简单基线解决方案。这表明 LLM 在某些图表任务上仍有改进空间。
TalkGraph5-ModelCap结果
模型容量对 PaLM 2-XXS、XS、S 和 L 图形推理任务的影响。
不同的图形形状是否会混淆 LLM
我们想知道图的“形状”(节点的连接方式)是否会影响 LLM 解决问题的能力。请将下图视为图形状的不同示例。
TalkGraph6-样本
使用 GraphQA 的不同图生成器生成的图样本。ER、BA、SBM 和 SFN 分别指的是Erdős–Rényi、Barabási–Albert、随机块模型和无标度网络。
我们发现图结构对 LLM 性能有很大影响。例如,在询问是否存在循环的任务中,LLM 在紧密互连的图(循环在那里很常见)上表现出色,但在路径图(循环永远不会发生)上却表现不佳。有趣的是,提供一些混合示例有助于它适应。例如,对于循环检查,我们在提示中添加了一些包含循环的示例和一些没有循环的示例作为少样本示例。其他任务也出现了类似的模式。
TalkGraph7-生成器结果
比较不同图形生成器在不同图形任务上的表现。这里的主要观察结果是图形结构对 LLM 的性能有显著影响。ER、BA、SBM 和 SFN 分别指Erdős–Rényi、Barabási–Albert、随机块模型和无标度网络。
结论
简而言之,我们深入研究了如何以文本形式最好地表示图表,以便法学硕士能够理解它们。我们发现了三个主要因素:
如何将图形转换为文本:我们如何将图形表示为文本会显著影响 LLM 性能。事件编码在大多数任务中都表现出色。
任务类型:即使图表到文本的转化很好,某些类型的图表问题对于 LLM 来说也更难。
图形结构:令人惊讶的是,我们进行推理的图形的“形状”(连接密集、稀疏等)会影响 LLM 的表现。
这项研究揭示了有关如何为 LLM 准备图表的关键见解。正确的编码技术可以显著提高 LLM 的图表问题准确率(提高幅度从 5% 左右到 60% 以上)。我们的新基准 GraphQA 将有助于推动该领域的进一步研究。
致谢
我们要感谢我们的合著者 Jonathan Halcrow 对这项工作做出的宝贵贡献。我们衷心感谢 Anton Tsitsulin、Dustin Zelle、Silvio Lattanzi、Vahab Mirrokni 以及 Google Research 的整个图形挖掘团队,感谢他们的深刻评论、彻底校对和建设性反馈,大大提高了我们工作的质量。我们还要特别感谢 Tom Small 制作了本文中使用的动画。
评论