 我们推出了 Cappy,这是一个小型预训练评分器模型,它可提高并超越大型多任务语言模型的性能。我们通过 PromptSource 和 Big-Bench 的各种复杂任务评估了此预训练评分器的有效性。
我们推出了 Cappy,这是一个小型预训练评分器模型,它可提高并超越大型多任务语言模型的性能。我们通过 PromptSource 和 Big-Bench 的各种复杂任务评估了此预训练评分器的有效性。
大型语言模型 (LLM) 的进步催生了一种新范式,该范式将各种自然语言处理 (NLP) 任务统一在一个指令遵循框架内。最近的多任务 LLM(例如T0、FLAN和OPT-IML)就是这种范式的典型代表。首先,收集多任务数据,每个任务都遵循特定于任务的模板,其中每个标记的示例都转换为指令(例如,“将概念组合成一个句子:滑雪、山、滑雪者”),并配以相应的响应(例如,“滑雪者从山上滑雪下来”)。这些指令-响应对用于训练 LLM,从而产生一个条件生成模型,该模型将指令作为输入并生成响应。此外,多任务 LLM 表现出卓越的任务泛化能力,因为它们可以通过理解和解决全新的指令来解决前所未见的任务。
Cappy 指令执行 (1)
多任务 LLM(例如 FLAN)的指令跟随预训练的演示。此范式下的预训练任务可提高未见任务的性能。
由于理解和仅使用指令解决各种任务的复杂性,多任务 LLM 的大小通常从几十亿个参数到数千亿个参数不等(例如FLAN-11B、T0-11B和OPT-IML-175B)。因此,运行如此大规模的模型带来了重大挑战,因为它们需要相当大的计算能力,并对 GPU 和 TPU 的内存容量提出了很高的要求,从而使其训练和推理成本高昂且效率低下。需要大量存储来为每个下游任务维护唯一的 LLM 副本。此外,最强大的多任务 LLM(例如 FLAN-PaLM-540B)是闭源的,因此无法进行调整。然而,在实际应用中,利用单个多任务 LLM 以零样本方式管理所有可能的任务仍然很困难,特别是在处理复杂任务、个性化任务以及无法使用指令简洁定义的任务时。另一方面,如果不结合丰富的先验知识,下游训练数据的大小通常不足以很好地训练模型。因此,长期以来,人们一直希望将 LLM 与下游监督相结合,同时绕过存储、内存和访问问题。
某些参数高效的调优策略(包括快速调优和适配器)大大降低了存储需求,但它们在调优过程中仍通过 LLM 参数执行反向传播,从而保持较高的内存需求。此外,一些上下文学习技术通过将有限数量的监督示例集成到指令中来规避参数调优。然而,这些技术受到模型最大输入长度的限制,这只允许少数样本来指导任务解决。
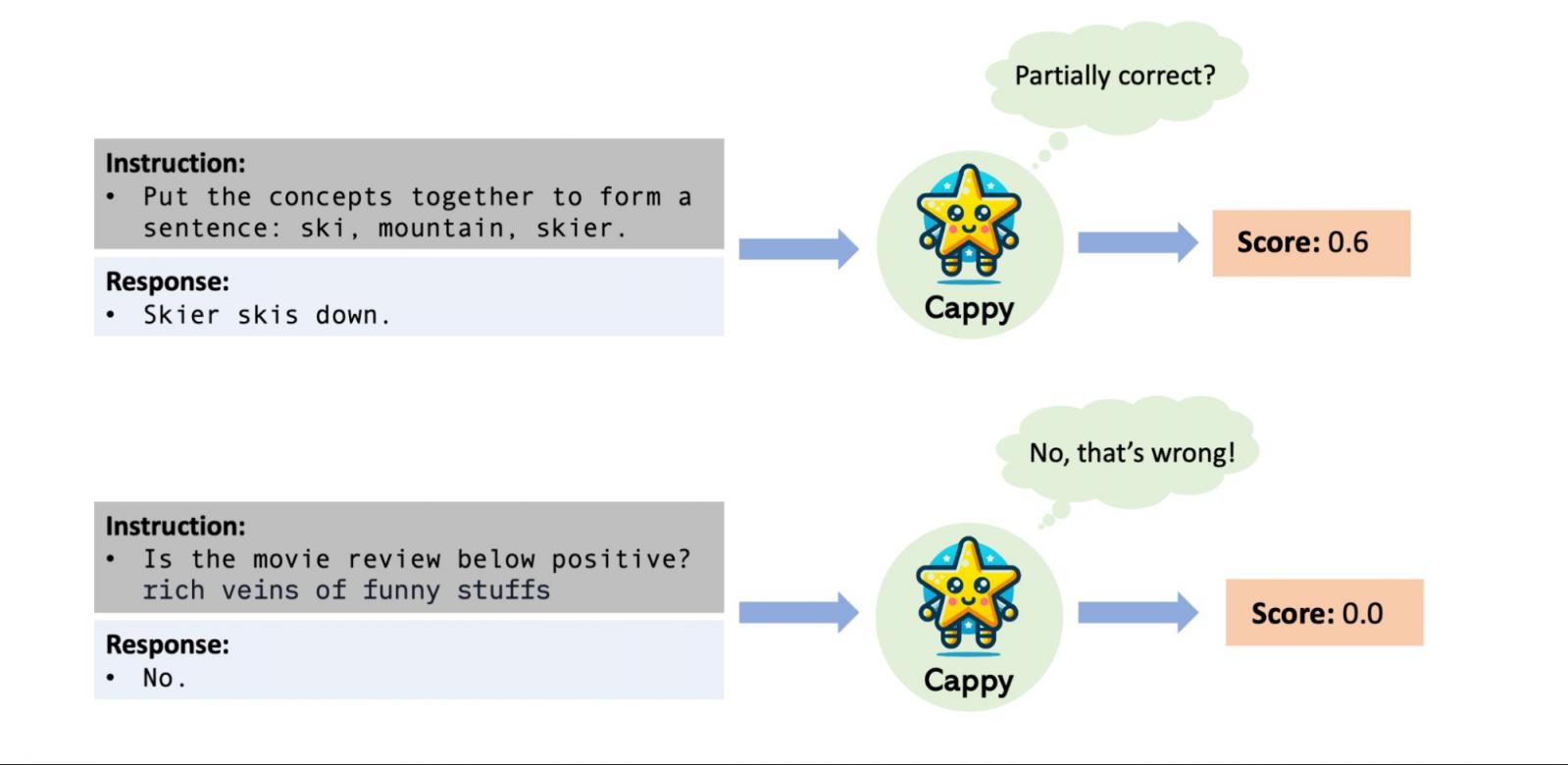
在NeurIPS 2023上发表的“ Cappy:使用小型评分器超越并提升大型多任务 LM ”中,我们提出了一种提高多任务 LLM 性能和效率的新方法。我们引入了一个轻量级的预训练评分器 Cappy,它基于RoBERTa上的持续预训练,仅包含 3.6 亿个参数。Cappy 将指令和候选响应作为输入,并产生 0 到 1 之间的分数,表示响应相对于指令的估计正确性。Cappy 可以独立完成分类任务,也可以作为 LLM 的辅助组件,从而提高其性能。此外,Cappy 可以有效地实现下游监督而无需任何微调,从而避免了通过 LLM 参数进行反向传播的需要并减少了内存需求。最后,使用 Cappy 进行适配不需要访问 LLM 参数,因为它与闭源多任务 LLM(例如仅通过 WebAPI 访问的 LLM)兼容。
卡皮英雄
Cappy 将指令和响应对作为输入,并输出从 0 到 1 的分数,表示对响应相对于指令的正确性的估计。
预训练
我们从相同的数据集集合开始,其中包括来自PromptSource的 39 个用于训练T0的不同数据集。此集合涵盖各种任务类型,例如问答、情绪分析和摘要。每个数据集都与一个或多个模板相关联,这些模板将原始数据集中的每个实例转换为与其基本事实响应配对的指令。
Cappy 的回归模型要求每个预训练数据实例都包含一个指令-响应对以及响应的正确性注释,因此我们生成一个正确性注释范围从 0 到 1 的数据集。对于生成任务中的每个实例,我们利用现有的多任务 LLM 通过采样生成多个响应,并以给定的指令为条件。随后,我们使用响应与实例的基本事实响应之间的相似性,为由指令和每个响应形成的对分配注释。具体来说,我们使用Rouge-L来计算这种相似性作为一种弱监督形式,这是一种常用的衡量整体多任务性能的指标,已证明与人工评估高度一致。
结果,我们获得了一个包含 1.6 亿个实例的有效回归数据集,并附有正确性分数注释。最终的 Cappy 模型是在RoBERTa模型上使用回归数据集进行持续预训练的结果。Cappy 的预训练是在 Google 的TPU-v4上进行的,使用的是RedCoast,这是一种用于自动化分布式训练的轻量级工具包。
Cappy 数据增强
使用多任务 LLM 进行数据增强,为 Cappy 的预训练和微调构建弱监督回归数据集。
应用 Cappy
Cappy 通过候选选择机制解决实际任务。更具体地说,给定一条指令和一组候选答案,Cappy 会为每个候选答案生成一个分数。这是通过在每个答案旁边输入指令,然后将得分最高的答案分配为其预测来实现的。在分类任务中,所有候选答案都是预先定义的。例如,对于情绪分类任务的指令(例如,“根据此评论,用户会推荐此产品吗?:‘即使对于非游戏玩家来说也很棒。’”),候选答案是“是”或“否”。在这种情况下,Cappy 独立运行。另一方面,在生成任务中,候选答案不是预先定义的,需要现有的多任务 LLM 来生成候选答案。在这种情况下,Cappy 充当多任务 LLM 的辅助组件,增强其解码能力。
使用 Cappy 调整多任务 LLM
当有可用的下游训练数据时,Cappy 可使多任务 LLM 有效且高效地适应下游任务。具体来说,我们对 Cappy 进行微调,以将下游任务信息整合到 LLM 预测中。此过程涉及使用与构建预训练数据相同的数据注释过程创建特定于下游训练数据的单独回归数据集。因此,经过微调的 Cappy 与多任务 LLM 协作,提升了 LLM 在下游任务上的性能。
与其他 LLM 调优策略相比,使用 Cappy 调优 LLM 可显著降低对设备内存的高需求,因为它避免了通过 LLM 参数进行下游任务反向传播的需要。此外,Cappy 调优不依赖于对 LLM 参数的访问,使其与闭源多任务 LLM(例如仅通过 WebAPI 访问的 LLM)兼容。与通过将训练示例附加到指令前缀来规避模型调优的上下文学习方法相比,Cappy 不受 LLM 最大输入长度的限制。因此,Cappy 可以合并无限数量的下游训练示例。Cappy 还可以与其他调优方法(如微调和上下文学习)一起应用,从而进一步提高其整体性能。
Cappy下游适应
Cappy 与依赖 LLM 参数(例如微调和快速调整)的方法之间的下游适应性比较。Cappy 的应用程序增强了多任务 LLM。
结果
我们对PromptSource中的 11 个语言理解分类任务中的 Cappy 性能进行了评估。我们证明,具有 3.6 亿个参数的 Cappy 性能优于 OPT-175B 和 OPT-IML-30B,并且与现有最佳多任务 LLM(T0-11B 和 OPT-IML-175B)的准确率相当。这些发现凸显了 Cappy 的能力和参数效率,这归功于其基于评分的预训练策略,该策略通过区分高质量和低质量的响应来整合对比信息。相反,以前的多任务 LLM 完全依赖于仅使用基本事实响应的教师强制训练。
Cappy 准确度
PromptSource 的 11 个测试任务的总体准确率平均值。“RM” 指的是预先训练的 RLHF 奖励模型。Cappy 在现有的多任务 LLM 中堪称佼佼者。
我们还研究了使用 Cappy 的多任务 LLM 在BIG-Bench的复杂任务上的适应性,BIG-Bench 是一组手动策划的任务,被认为超出了许多 LLM 的能力。我们专注于所有 45 代 BIG-Bench 任务,特别是那些不提供预设答案选项的任务。我们使用 Rouge-L 分数(表示模型代与相应基本事实之间的整体相似性)在每个测试集上评估性能,并报告 45 项测试的平均分数。在此实验中,FLAN-T5 的所有变体都用作骨干 LLM,基础 FLAN-T5 模型被冻结。这些结果(如下所示)表明,Cappy 大幅提高了 FLAN-T5 模型的性能,其表现始终优于通过使用 LLM 本身的自评分进行样本选择所实现的最有效基线。
Cappy 平均 Rouge-L 得分
BIG-Bench 中 45 个复杂任务的平均 Rouge-L 得分。x 轴表示不同大小的 FLAN-T5 模型。每条虚线代表一种适用于 FLAN-T5 的方法。自评分是指使用 LLM 的交叉熵来选择响应。Cappy 大大提高了 FLAN-T5 模型的性能。
结论
我们引入了 Cappy,这是一种可提高多任务 LLM 性能和效率的新方法。在我们的实验中,我们使用 Cappy 将单个 LLM 适配到多个领域。未来,Cappy 作为预训练模型可能会以其他创造性的方式用于单个 LLM 之外。
致谢
感谢 Bowen Tan、Jindong Chen、Lei Meng、Abhanshu Sharma 和 Ewa Dominowska 提供的宝贵反馈。我们还要感谢 Eric Xing 和 Zhiting Hu 提出的建议。
评论