我们提出了一个理解医学成像中的人工智能模型的框架,利用生成人工智能和跨学科专家评审来识别和解释与模型预测相关的视觉线索。
机器学习 (ML) 有可能彻底改变医疗保健,从减少工作量和提高效率到发现新的生物标志物和疾病信号。为了负责任地利用这些优势,研究人员采用可解释性技术来了解 ML 模型如何进行预测。但是,当前基于显着性的方法会突出显示重要的图像区域,通常无法解释特定的视觉变化如何驱动 ML 决策。可视化这些变化(我们称之为“属性”)有助于探究通过定量指标不易发现的偏见方面,例如如何整理数据集、如何训练模型、问题的制定以及人机交互。这些可视化还可以帮助研究人员了解这些机制是否可能代表进一步研究的新见解。
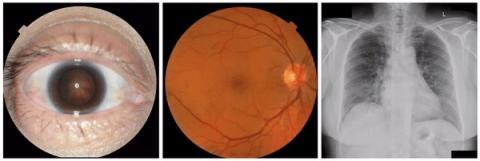
在《柳叶刀电子生物医学》杂志发表的《使用生成式人工智能研究医学图像模型和数据集》中,我们探索了生成模型在增强我们对医学成像 ML 模型的理解方面的潜力。基于之前发布的StylEx 方法(该方法可生成分类器的视觉解释),我们的目标是开发一种可广泛应用于医学成像研究的通用方法。为了测试我们的方法,我们根据最近的科学文献选择了三种成像模式(外部眼部照片、眼底照片和胸部 X 光 [CXR])和八个预测任务。这些包括已建立的临床任务作为“阳性对照”,其中已知属性有助于预测,还包括临床医生未接受过培训的任务。对于外部眼部照片,我们检查了能够从眼前部图像中检测出疾病迹象的分类器。对于眼底照片,我们检查了在预测心血管风险因素方面表现出惊人效果的分类器。此外,对于 CXR,我们检查了异常分类器以及令人惊讶的预测种族的能力。
GenAI 框架用于研究医学图像模型和数据集
我们的框架分为四个关键阶段:
分类器训练:
我们训练 ML 分类器模型来执行特定的医学成像任务,例如检测疾病迹象。此步骤后,模型将冻结。如果感兴趣的模型已经可用,则可以在冻结状态下使用它,而无需进一步修改此模型。
StylEx 训练:
然后,我们训练StylEx生成模型,其中包括基于StyleGAN-v2的图像生成器和两个额外损失。第一个额外损失是自动编码器损失,它教导生成器创建类似于输入图像的输出图像。第二个损失是分类器损失,它鼓励生成图像的分类器概率与输入图像的概率相同。这些损失共同使生成器能够生成既看起来逼真又保留分类器预测的图像。
自动属性选择:
我们使用 StylEx 模型通过为一组图像创建反事实可视化来自动生成视觉属性。每个反事实可视化都基于真实图像,但使用 StylEx 生成器进行修改,同时每次更改一个属性(见下方动画)。然后,对属性进行筛选和排序,以保留对分类器决策影响最大的属性。
专家小组审查:
最后,由相关临床专家、社会科学家等组成的跨学科专家小组分析确定的属性,并在医学和社会背景下进行解释。
StylEx-1-流程图
我们的方法流程图说明了四个主要步骤,包括 (1) 为感兴趣的预测任务开发 ML 分类器;(2) 开发生成性 StylEx ML 模型来检查冻结分类器;(3) 使用生成模型生成视觉属性并提取最具影响力的视觉属性;(4) 让跨学科小组检查特征以尽量减少解释中的盲点。
阳性对照
首先,为了确保框架能够成功识别已知的视觉属性,我们检查了每种成像方式的任务,其中存在一些已知属性(即“阳性对照”实验)。事实上,我们发现,皮质白内障辐条在根据外眼照片预测白内障时可见,视网膜静脉扩张在根据眼底照片预测吸烟状况时可见,左心室扩大在根据 CXR 预测异常时可见。
StylEx-0-英雄
通过我们的方法提取的“已知”(阳性对照)属性的示例:a)轮辐表示白内障存在,其表现为像车轮轮辐一样的放射状混浊;b)视网膜静脉扩张表示吸烟状况;c)左心室扩大表示异常 CXR。
可能的新信号
我们还发现了一些视觉上惊人但又耐人寻味的关联。一个例子是眼睑边缘苍白度增加与 HbA1c 水平升高相关。这一观察结果与之前的 研究一致,表明睑板腺疾病与糖尿病之间存在联系,这可能为进一步研究潜在机制铺平了道路。
StylEx-3-糖化血红蛋白
眼睑边缘苍白的例子,这是与预测的 HbA1c(血糖测量指标)较高相关的特征。
可能的混淆因素
我们还发现了一个令人惊讶、事后看来显而易见且发人深省的结果:眼线粗细和密度增加与血红蛋白水平降低相关。这一发现可能反映了数据集中的混杂因素,因为女性更常使用化妆品,而她们的血红蛋白水平往往低于男性。这凸显了在解释 ML 模型输出时考虑数据集偏见和与社会文化因素相关的怪癖的重要性。
StylEx-4-混杂因素
以眼线为例,眼线是一种与预测血红蛋白较低相关的属性,女性和老年人的血液测量值较低。
同样,在检查之前发表的 AI 模型可以根据放射图像识别种族的研究时,出现了一个与锁骨角度/位置相关的特征。从不同角度拍摄 CXR 时也能看到这一属性:后-前 (PA,为站立的门诊患者拍摄) 与前后 (AP,为躺在病床上的患者拍摄)。在这个数据集中,我们验证了 PA 和 AP 图像中自我报告种族的比例不同,其方向性与观察到的属性一致。这种关联可能是由于多种因素造成的,包括数据集收集过程、医疗保健访问或患者人群方面。
StylEx-5-混杂因素
与自我报告的种族相关的锁骨明显向下位移的示例。动画以 2 帧之间的闪烁形式呈现,以强调差异。
产生假设,而非因果关系
虽然我们的框架提供了宝贵的可解释见解,但必须承认,它并没有建立因果关系,而是为人类解释和进一步研究提供了属性。因此,跨学科合作对于确保严谨的解释至关重要。专家小组审查得出结论,观察到的几个关联可能受到模型未捕捉到的未测量变量或复杂关系的影响,并且与生理学无关,包括结构和社会因素对健康结果、数据集人口统计或构成以及人类与技术的互动的影响。专家小组还得出结论,一些关联可能揭示新现象,并建议进行研究以支持此类发现。
我们将这些经验总结为一个通用框架,我们称之为“推进公平可解释人工智能的跨学科专家小组”。该框架可用于指导对 ML 模型结果的跨学科探索,目的是帮助减少偏见、识别潜在的混杂因素,并在 ML 模型结果解释文献存在空白的情况下寻找进一步研究的机会。反过来,这些见解可以为 ML 模型改进提供机会。对于解释属性,关联被归类为 a) 已知关联;b) 在临床文献中已知,可能需要进一步统计检查;c) 新的关联,需要进一步调查;或 d) 存在混杂或其他偏见的可能性很高,强烈建议进一步调查。
结论
我们的研究证明了生成模型在增强医学成像中 ML 模型可解释性的潜力。通过将技术进步与跨学科专业知识相结合,我们可以负责任地利用人工智能来发现新知识、改善医疗诊断并解决医疗保健中的偏见。我们鼓励在这一领域进一步研究,并强调 ML 研究人员、临床医生和社会科学家之间合作的重要性。
致谢
作者感谢阿波罗国际放射学研究所的 Sreenivasa Raju Kalidindi 博士及其团队对阿波罗数据集的帮助,感谢 Andrew Sellergren 和 Zaid Nabulsi 对 CXR 建模基础设施的帮助,感谢 Jorge Cuadros 博士和 Lauren P. Daskivich 博士对 EyePACS/LACDHS 数据集的帮助,感谢 Elvia Figueroa 和 LAC DHS TDRS 项目工作人员对数据收集和项目支持的帮助,感谢 Nikhil Kookkiri 和 EyePACS 工作人员对数据收集和支持的帮助,感谢 Preeti Singh 对数据集和注释物流的支持。最后,作者要感谢 Avinash Varadarajan、Inbar Mosseri 和 Yossi Gandelsman 对项目的早期反馈,感谢 Cameron Chen、Ivor Horn 和 Lily Peng 对 Lancet eBioMedicine 手稿的反馈,感谢 Tiya Tiyasirichokchai 对图表设计的帮助。作者还要感谢 Stephen Pfohl、Jessica Schrouff、Sami Lachgar、Lauren Winer 和 Dale Webster 对跨学科专家小组框架手稿的反馈和支持。
评论