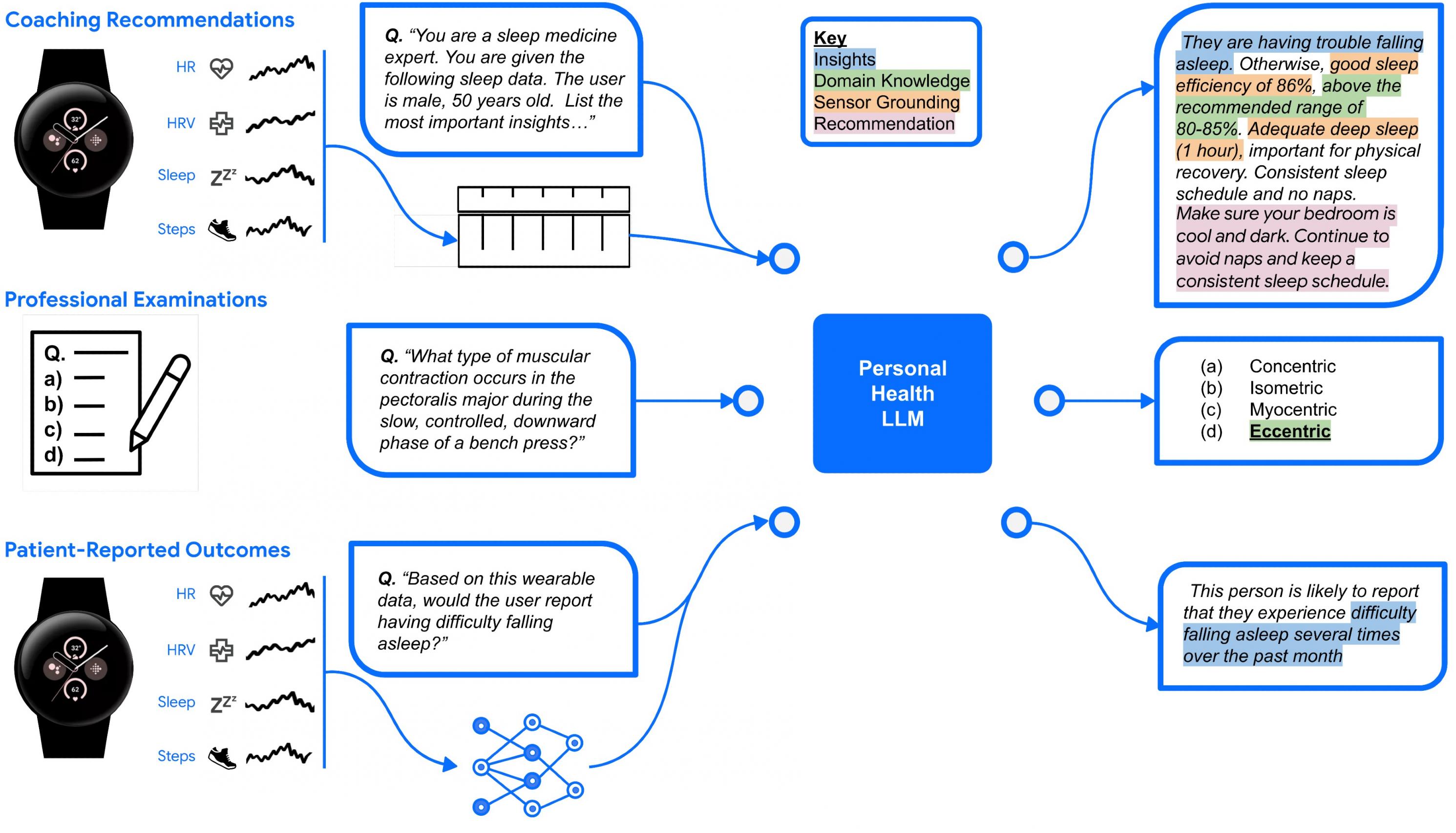
我们的研究引入了一种新颖的大型语言模型,旨在理解和推理个人健康问题和数据。为了系统地评估我们的模型,我们整理了一组三个基准数据集,用于测试专家领域知识、与患者报告结果的一致性以及提供人性化质量建议的能力。
移动和可穿戴设备可以提供有关个人生理状态和行为的连续、细粒度和纵向数据。示例包括步数、原始传感器测量值(如心率变异性)、睡眠时间等。个人可以使用这些数据进行个人健康监测以及激励健康行为。这是一个令人兴奋的领域,其中生成式 AI 模型可用于向个人提供额外的个性化见解和建议,以帮助他们实现健康目标。然而,要做到这一点,模型必须能够推理由复杂时间序列和零星信息(如锻炼日志)组成的个人健康数据,使用相关的个人健康领域知识将这些数据情境化,并根据个人的健康背景产生个性化的解释和建议。
考虑一个常见的健康问题,“我怎样才能睡得更好?”虽然这个问题看似简单,但要得到针对个人的定制答案需要执行一系列复杂的分析步骤,例如:检查数据可用性、计算平均睡眠时间、识别一段时间内的睡眠模式异常、将这些发现与个人的整体健康状况联系起来、整合对人群睡眠规范的了解,并提供个性化的睡眠改善建议。最近,我们展示了如何利用Gemini 模型在多模态和长上下文推理方面的高级能力,在各种医疗任务上实现最先进的性能。然而,这类任务很少使用与个人健康监测相关的来自移动和可穿戴设备的复杂数据。
基于 Gemini 模型的下一代功能,我们提出的研究重点介绍了两种使用 LLM 提供准确的个人健康和保健信息的互补方法。第一篇论文“迈向个人健康大型语言模型”表明,根据专家分析和自我报告结果进行微调的 LLM 能够成功地将生理数据情境化以用于个人健康任务。第二篇论文“使用大型语言模型代理将可穿戴数据转化为个人健康洞察”强调了代码生成和基于代理的工作流程的价值,以便通过自然语言查询准确分析行为健康数据。我们相信,将这些想法结合在一起,实现对个人健康数据的交互式计算和扎实推理,将是开发真正个性化的健康助手的关键要素。通过这两篇论文,我们在一系列个人健康任务中整理了新的基准数据集,这有助于评估这些模型的有效性。
迈向个人健康大语言模型
个人健康大型语言模型( PH-LLM) 是 Gemini 的微调版本,旨在生成见解和建议,以改善与睡眠和健身模式相关的个人健康行为。通过使用多模态编码器,PH-LLM 针对文本理解和推理以及原始时间序列传感器数据(例如可穿戴设备的心率变异性和呼吸频率)的解释进行了优化。
为了系统地评估 PH-LLM,我们创建并整理了一组三个基准数据集,用于测试:
该模型能够根据测量的个人睡眠模式、身体活动和生理反应为他们提供详细的见解和建议。
专家级领域知识。
预测自我报告的睡眠质量评估。
PHLLM1-英雄概览
为了评估 PH-LLM,我们整理了三个基准数据集,涵盖长篇辅导推荐任务、专家领域知识评估和自我报告睡眠结果预测。
对于洞察和建议任务,我们从美国用户同意的两个个人健康垂直领域(睡眠和健身)中创建了 857 个案例研究。这些案例研究是与领域专家合作设计的,代表了现实世界的指导场景,并通过使用文本表示解释时间序列生理数据来突出模型在理解、推理和指导方面的能力。通过对模型响应的全面评估,我们观察到Gemini Ultra 1.0和 PH-LLM 的表现与健身方面的专家表现在统计上没有差异。虽然专家撰写的建议在睡眠方面的评分更高,但表现接近,进一步微调 PH-LLM 可显著提高其在生成洞察和预测潜在因果因素时使用相关领域知识和个性化信息的能力。
PHLLM2-杆
根据人类专家的评估,对 PH-LLM 进行微调可提高其生成准确见解和睡眠中潜在致病因素的能力。这里我们展示了每个案例研究子部分评估标准中专家的平均评分(越高越好)。在适应性方面的表现与人类专家没有统计学差异。“∗”表示经过多重假设检验校正后,两种反应类型之间存在统计学上的显著差异。
为了进一步评估专家领域的知识,我们通过在线门户网站的人工测试者,以睡眠医学和健康认证考试的形式评估了 PH-LLM 在多项选择题数据集上的表现。PH-LLM 在睡眠方面取得了 79% (N =629 个问题)的成绩,在健康方面取得了 88% (N =99 个问题)的成绩,这两个成绩都超过了人类专家样本的平均分数(分别为 76% 和 71%),也超过了获得继续教育学分以维持这些领域专业执照的基准。
PHLLM3-表
AMA = 美国医学协会、PRA = 医师认可奖、ABIM = 美国内科医学委员会、MOC = 维护认证、CME = 继续医学教育、NSCA = 国家体能协会、CSCS = 认证体能专家。
最后,为了使 PH-LLM 能够预测自我报告的睡眠质量评估,我们使用可穿戴传感器数据的文本和多模态编码表示,对经过验证的睡眠中断和睡眠障碍调查问题的回答对模型进行了训练。如下所示,我们证明了多模态编码是实现与仅用于预测这些结果的判别模型相当的性能的必要条件和充分条件。
PHLLM4-AUROC
PH-LLM 模型变体对自我报告睡眠结果的预测 AUROC性能。使用适配器对多模态传感器数据进行编码,在 16 个结果中的 12 个结果(用“*”表示)中,其性能优于零样本和少量样本提示的等效文本表示,且具有统计意义。
总的来说,这些结果证明了调整 PH-LLM 来为个人健康应用提供生理数据背景的好处。
将可穿戴数据转化为个人健康见解
LLM 可以通过软件工具进行增强以扩展其功能,例如代码生成和信息检索。基于 LLM 的代理具有迭代推理和与工具交互的能力,这为将其推理能力扩展到复杂、时间的可穿戴数据提供了一种有前途的方法。在我们的第二篇论文中,我们介绍了一个基于 Gemini Ultra 1.0 的个人健康洞察代理框架。该代理利用Gemini 模型的强大功能以及代理框架、代码生成功能和信息检索工具来迭代分析原始可穿戴数据并为健康查询提供个性化的解释和建议。这种组合使代理能够:
分析可穿戴设备的数据:代理使用 Python 解释器分析可穿戴设备的多维时间序列数据,执行复杂的计算并识别趋势。
整合额外的健康知识:代理通过搜索引擎访问知识库,将最新的医疗和健康信息纳入其响应中。
提供个性化的见解:代理通过个人数据、医学知识和特定用户查询进行迭代多步骤推理,生成定制的见解和建议。
此示例展示了代理如何逐步推理个人健康查询。这仅用于说明目的。
为了评估代理的能力,我们整理了两个数据集:一个用于测试代理在健康查询中的数值准确性,另一个用于通过人工注释评估其在开放式健康查询中的推理和代码的质量。
在第一个数据集“客观健康洞察查询”中,该代理在 4,000 个客观个人健康洞察查询的数据集上实现了 84% 的准确率,展示了其处理数字推理和数据分析的能力。
PHLLM6-杆
我们的代理在客观的个人健康洞察查询中得分高于代码生成和标准 LLM 数值推理基线。准确度基于精确匹配,精度在两位数以内。
在第二个数据集“开放式健康洞察查询”中,我们评估了代理在 172 个具有代表性的开放式个人健康查询中的表现,这些查询涉及 600 多个小时的人工评估,涵盖 6000 多个模型响应。总体而言,在 14 个评估轴中的 9 个方面,代理的性能显著优于非代理代码生成基线,包括领域知识、逻辑和推理质量等关键方面。
PHLLM7-结果
我们的人工和专家评估表明,我们的代理优于代码生成基线,这表明了迭代推理和工具使用的重要性。“∗”表示平均评分之间存在统计学上的显着差异。
虽然该代理专注于睡眠和健身数据,但其框架可以扩展以分析更广泛的健康信息,包括医疗记录、营养数据,甚至用户提供的日记条目。随着 LLM 的不断发展,代理有可能变得越来越复杂,并可能为个人健康管理提供更深入的见解和更有效的指导。
结论
我们的主要目标是研究可能有助于人们活得更长寿、更健康的特性和能力。睡眠和健身是人口健康的重要组成部分,也是全球过早死亡的预测指标。我们在案例研究、个人健康领域知识以及睡眠和健身方面的开放式查询方面的研究所实现的功能代表着朝着支持个性化见解和建议的 AI 模型迈出了有意义的一步,这些模型使个人能够从自己的健康数据中得出准确且可操作的结论。我们期待仔细测试并了解哪些功能对用户最有帮助。
致谢
此处描述的研究是 Google Research、Google Health、Google DeepMind 和合作团队的联合成果。
评论