在移动设备上实时、同步感知人体姿势、面部特征点和手部跟踪可以实现各种有影响力的应用,例如健身和运动分析、手势控制和手语识别、增强现实效果等。MediaPipe 是一个开源框架,专门为利用加速推理(例如 GPU 或 CPU)的复杂感知管道而设计,它已经为这些任务提供了快速、准确但独立的解决方案。将它们实时组合成一个语义一致的端到端解决方案是一个独特的难题,需要同时推理多个依赖的神经网络。
今天,我们很高兴地宣布推出MediaPipe Holistic,它是这一挑战的解决方案,它提供了一种新颖的先进人体姿势拓扑,可解锁新颖的用例。MediaPipe Holistic 由一个新的管道组成,该管道具有优化的姿势、面部和手部组件,每个组件都实时运行,其推理后端之间的内存传输最少,并且增加了对三个组件可互换性的支持,具体取决于质量/速度权衡。当包含所有三个组件时,MediaPipe Holistic 为突破性的 540 多个关键点(33 个姿势、21 个每手和 468 个面部关键点)提供了统一的拓扑,并在移动设备上实现近乎实时的性能。MediaPipe Holistic作为MediaPipe的一部分发布,可在移动设备(Android、iOS)和桌面设备上使用。我们还推出了 MediaPipe 新的即用型研究 API(Python)和 Web API(JavaScript),以简化对该技术的访问。

上图: MediaPipe 在运动和舞蹈用例上的整体结果。下图: “静音”和“你好”手势。请注意,我们的解决方案始终将手识别为右手(蓝色)或左手(橙色)。
管道和质量
MediaPipe Holistic 管道集成了针对姿势、面部和手部组件的独立模型,每个模型都针对其特定领域进行了优化。然而,由于它们有不同的专业化,一个组件的输入并不适合其他组件。例如,姿势估计模型以较低的固定分辨率视频帧 (256x256) 作为输入。但如果要从该图像中裁剪手部和面部区域以传递给各自的模型,图像分辨率将太低而无法准确表达。因此,我们将 MediaPipe Holistic 设计为多级管道,它使用适合区域的图像分辨率来处理不同的区域。
首先,MediaPipe Holistic 使用BlazePose 的姿势检测器和随后的关键点模型 估计人体姿势。然后,使用推断出的姿势关键点,它为每只手(2x)和脸部导出三个感兴趣区域 (ROI) 裁剪,并使用重新裁剪模型来改进 ROI(详情如下)。然后,管道将全分辨率输入帧裁剪到这些 ROI,并应用特定于任务的脸部和手部模型来估计其相应的关键点。最后,所有关键点与姿势模型的关键点合并,以产生完整的 540 多个关键点。
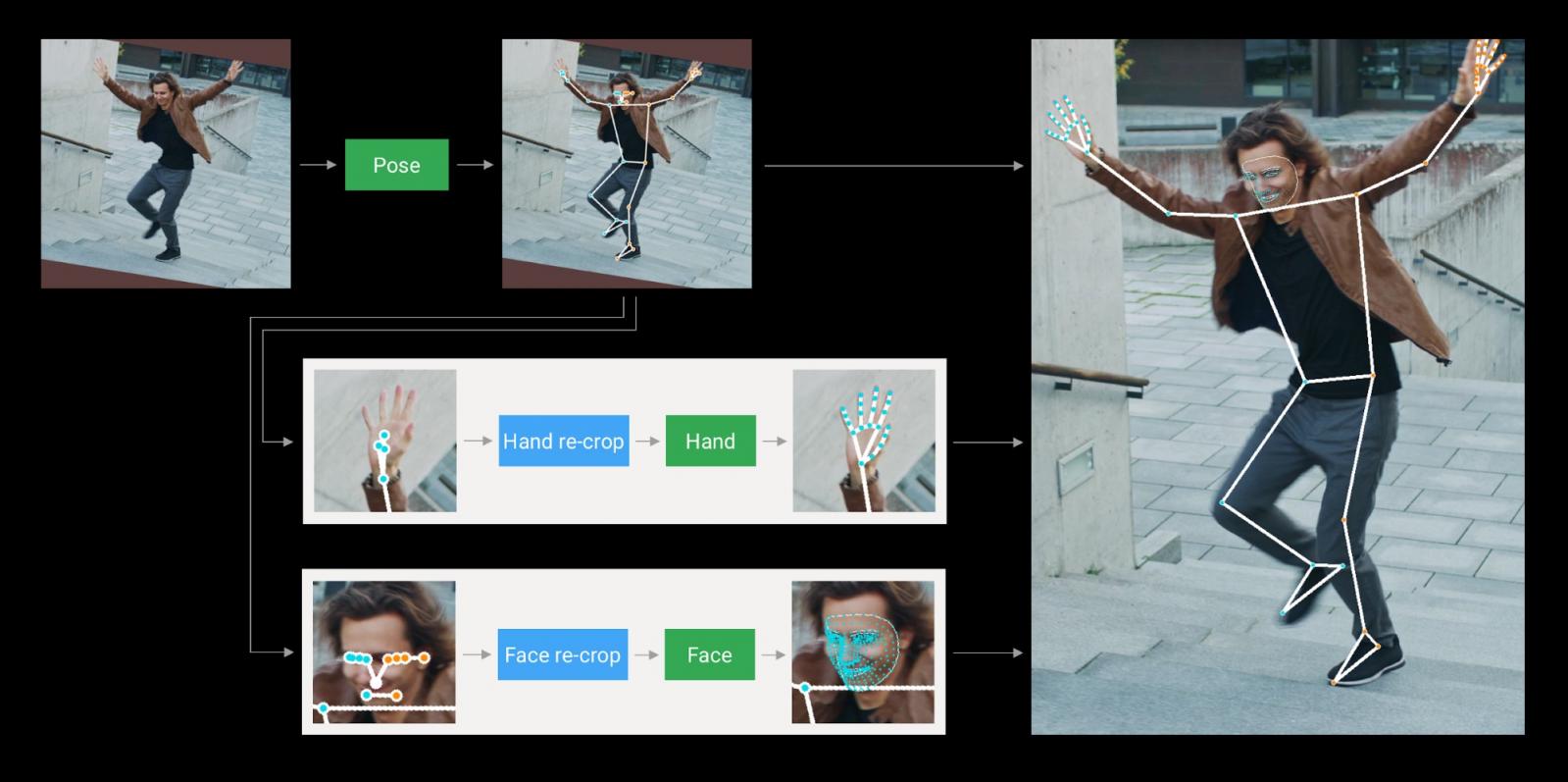
MediaPipe 整体管道概述。
为了简化 ROI 的识别,我们采用了一种类似于独立面部和手部管道所用的跟踪方法。这种方法假设对象在帧之间不会发生明显移动,并使用前一帧的估计值作为当前帧中对象区域的指导。然而,在快速移动期间,跟踪器可能会丢失目标,这需要检测器在图像中重新定位它。MediaPipe Holistic 使用姿势预测(在每一帧上)作为额外的 ROI,以减少管道对快速移动做出反应时的响应时间。这还使模型能够保持整个身体及其部位的语义一致性,防止将帧中一个人的左手和右手或身体部位与另一个人混淆。
此外,姿势模型的输入帧分辨率很低,因此生成的脸部和手部 ROI 仍然不够准确,无法指导这些区域的重新裁剪,这需要精确的输入裁剪才能保持轻量级。为了缩小这一准确度差距,我们使用轻量级的脸部和手部重新裁剪模型,这些模型充当空间变换器的角色,并且仅花费相应模型推理时间的约 10%。
轻微鼻塞 弗莱明
跟踪管道(基线) 9.8% 3.1%
无需重新种植的管道 11.8% 3.5%
重新种植的管道 9.7% 3.1%
手部预测质量。每只手的平均误差 (MEH) 由手的大小来归一化。面部特征点误差 (FLE) 由瞳孔间距来归一化。
表现
MediaPipe Holistic 每帧需要最多 8 个模型之间的协调——1 个姿势检测器、1 个姿势标志模型、3 个重新裁剪模型和 3 个手部和面部关键点模型。在构建此解决方案时,我们不仅优化了机器学习模型,还优化了预处理和后处理算法(例如,仿射变换),由于管道复杂性,这些算法在大多数设备上都需要花费大量时间。在这种情况下,将所有预处理计算移至 GPU 可使整体管道速度提高约 1.5 倍(具体取决于设备)。因此,即使在中端设备和浏览器中,MediaPipe Holistic 也能以近乎实时的性能运行。
电话 第一人称射击游戏
Google Pixel 2 XL 18
三星 S9+ 20
15 英寸 MacBook Pro 2017 15
在各种中端设备上的性能,以每秒帧数 (FPS) 为单位进行测量。
管道的多级特性提供了另外两个性能优势。由于模型大多是独立的,因此可以根据性能和准确性要求将它们替换为更轻或更重的版本(或完全关闭)。此外,一旦推断出姿势,就可以准确地知道手和脸是否在帧范围内,从而使管道可以跳过对这些身体部位的推断。
应用
MediaPipe Holistic 拥有 540 多个关键点,旨在实现对肢体语言、手势和面部表情的全面、同步感知。其混合方法可实现远程手势界面以及全身 AR、运动分析和手语识别。为了展示 MediaPipe Holistic 的质量和性能,我们构建了一个简单的远程控制界面,该界面在浏览器中本地运行,可实现引人注目的用户交互,无需鼠标或键盘。用户可以操纵屏幕上的对象,坐在沙发上时在虚拟键盘上打字,以及指向或触摸特定的面部区域(例如静音或关闭摄像头)。它依靠准确的手部检测,随后的手势识别映射到固定在用户肩膀上的“触控板”空间,从而实现距离最远 4 米的远程控制。
当其他人机交互方式不方便时,这种手势控制技术可以解锁各种新颖的用例。在我们的网络演示中试用它并用它来制作您自己的想法的原型。

浏览器内无触摸控制演示。左图:手掌选择器、触摸界面、键盘。右图:远距离无触摸键盘。试试看吧!
用于研究和网络的 MediaPipe
为了加速 ML 研究及其在 Web 开发者社区中的应用,MediaPipe 现在提供现成的、可定制的Python和JavaScript ML 解决方案。我们从以前的出版物开始:Face Mesh、Hands和Pose,包括MediaPipe Holistic,还有更多。直接在 Web 浏览器中尝试它们:对于 Python,使用Google Colab 上 MediaPipe中的笔记本,对于 JavaScript,使用CodePen 上 MediaPipe中您自己的网络摄像头输入!
结论
我们希望 MediaPipe Holistic 的发布能够激励研发社区成员构建新的独特应用程序。我们预计这些管道将为未来研究具有挑战性的领域开辟道路,例如手语识别、非接触式控制界面或其他复杂用例。我们期待看到您能用它构建什么!

复杂而动态的手势。视频由Bill Vicars 博士制作,经许可使用。
致谢
特别感谢与我们一起从事技术工作的所有团队成员:Fan Zhang、Gregory Karpiak、Kanstantsin Sokal、Juhyun Lee、Hadon Nash、Chuo-Ling Chang、Jiuqiang Tang、Nikolay Chirkov、Camillo Lugaresi、George Sung、Michael Hays、 Tyler Mullen、Chris McClanahan、Ekaterina Ignasheva、Marat Dukhan、Artsiom Ablavatski、Yury Kartynnik、Karthik Raveendran、Andrei Vakunov、Andrei Tkachenka、Suril Shah、Buck Bourdon、明光勇、Esha Uboweja、Siarhei Kazakou、Andrei Kulik、Matsvei Zhdanovich 和马蒂亚斯·格伦德曼。
评论