
我们认为,对于某些类型的计算和内存而言,晶圆级计算是一个有趣且不可避免的概念。但不可避免的是,您需要做的工作超出了单个晶圆的核心所能提供的范围,然后您就会遇到同样的网络问题。
但不要想得太远。科学和数据分析仍需完成,而且有些地方需要这些方形核心和 SRAM 内存,例如由 AI 初创公司和 HPC 参与者 Cerebras Systems 创建的三代 Wafer Scale Engine 设备,它们可以驱动大型 GPU 加速机器。
这就是为什么劳伦斯利弗莫尔国家实验室利弗莫尔计算首席技术官 Bronis de Supinski早在 2023 年 7 月就告诉我们,该实验室正在与 AI 新贵 Cerebras Systems 和 SambaNova Systems 合作,以了解他们的架构如何用于管理美国的核武器库存和美国海军的核动力舰队。这是所谓的三实验室的任务之一,该实验室由劳伦斯利弗莫尔、桑迪亚国家实验室和洛斯阿拉莫斯国家实验室组成,它们都是美国能源部的一部分,该部门为该国最大的超级计算机提供资金,并负责管理国家核安全局。
事实证明,Cerebras 正与 TriLabs 合作解决六个不同的问题。作为本周 ISC24 庆祝活动的一部分,Cerebras 和 TriLabs 的研究人员发表了一篇论文,介绍了与核储备管理相关的分子动力学应用如何加速 179 倍,与橡树岭国家实验室的“Frontier”超级计算机上运行的相同应用程序相比,橡树岭国家实验室也是美国能源部的设施,但不是国家核安全局的正式组成部分。(您可以通过此链接查看该论文。)TriLabs 自主开发的分子动力学模拟也在劳伦斯利弗莫尔的“Quartz”CPU 专用集群上运行。
问题的关键就在这里,它与现代大规模并行超级计算机的弱扩展性以及单个计算引擎的强大扩展性有关,而这实际上归结为所有计算元素及其本地内存之间的高带宽。对于像 Frontier 和 Quartz 这样的大规模并行系统,这些系统的弱扩展性允许模拟大量原子及其相互作用。
正如论文所指出的,这些 MD 应用程序可以用飞秒时间步长解析原子振动,并可以模拟数十亿到数十万亿个原子。但是当你把所有时间加起来时,模拟最多只能显示几微秒的原子相互作用,而对于 TriLabs 和其他人想要模拟的物理和化学现象,有趣的行为只会发生在更长的时间尺度上大约 100 微秒或更长。论文中给出的例子包括核反应堆中辐射损伤的退火、热激活催化反应、接近平衡的相成核以及蛋白质折叠。
从定义上讲,晶圆级计算引擎是一种强大的扩展设备,因此 TriLabs 与 Cerebras 合作,将其嵌入式原子方法 (EAM) 模拟移植到其 CS-2 系统中的第二代 WSE-2 处理器上,该模拟运行在 1995 年最初由桑迪亚国家实验室和天普大学创建的大规模原子/分子大规模并行模拟器 (LAMMPS) 工具之上。具体模拟是将辐射照射到由钨、铜和钽制成的三种不同晶格中。在这些针对每个晶格中的 801,792 个原子的特定模拟中,想法是用辐射轰击晶格并观察会发生什么。在 Frontier 和 Quartz 机器上,模拟只能看到纳秒内的模拟,这不足以看到被辐射轰击的晶格会发生什么。
但是使用 WSE,每个核心可以模拟一个原子(并且仍然剩余一些核心)并将所有要处理的数据存储在本地 SRAM 中,与 GPU 相比,EAM/LAMMPS 模拟中每秒可处理的时间步数对于铜高 109 倍,对于钨高 96 倍,对于钽高 179 倍,给出几十毫秒的时间,因此足以观察晶格的实际情况。
如果您想测试您对色盲的敏感性,下面的图表显示了测试的节点数量、每焦耳电量的时间步长以及 WSE-2 相对于 Frontier 和 Quartz 机器的能效系数:
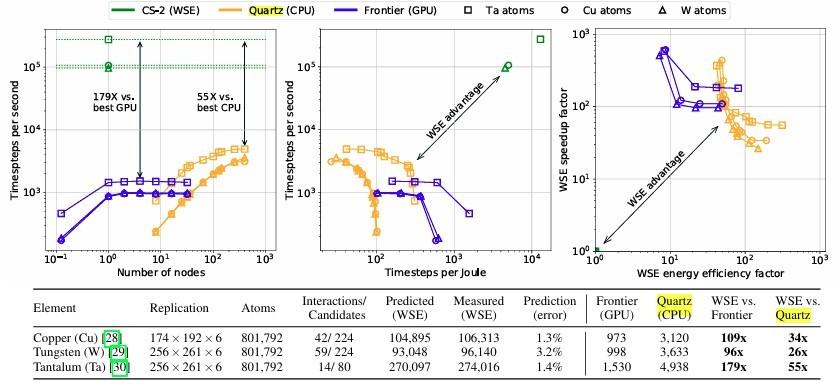
上图中有趣的是,配备 GPU 的 Frontier 系统在每秒模拟的时间步数方面逐渐减少,并且基于 CPU 的集群可以比 GPU 进一步扩展并驱动更多的时间步,但 WSE-2 仍然正如您在上面的图表和表格中看到的那样。
了解了这些结果后,我们来谈谈硬件。
WSE-2 引擎于 2021 年 4 月发布,采用台湾半导体制造公司 7 纳米工艺蚀刻而成。WSE-2 芯片拥有 2.6 万亿个晶体管和 850,000 个内核,配备 40 GB 的 SRAM 内存,总 SRAM 带宽为 20 PB/秒。您可能想知道为什么 TriLabs 没有在今年 3 月推出的较新的 WSE-3 设备上测试 EAM/LAMMPS 基准。好吧,使用 WSE-3 缩小到 5 纳米只会将内核数量增加到 900,000 个,只会将 SRAM 增加到 44 GB,将 SRAM 带宽增加到 21 PB/秒。使用 WSE-3 只能模拟稍大的原子集合,尽管每个内核的性能是 2 倍,模拟运行速度会提高一倍,或者也许能够提供每秒模拟时间步数的 2 倍。我们推测后者会很有用——例如,将钽晶格的模拟窗口从 WSE-2 上的 40 毫秒提升到 WSE-3 上的 80 毫秒左右。这几乎是人类尺度的时间。(眨眼,即自商业化互联网出现以来我们的平均注意力持续时间,约为 200 毫秒。)
橡树岭的 Frontier 超级计算机由带有定制 64 核“Trento”Epyc 处理器的节点组成,耦合到四个“Aldebaran”Instinct MI250X GPU 加速器;其中 9,408 个节点与 Hewlett Packard Enterprise 的 Slingshot 11 以太网变体捆绑在一起。但正如您从该测试中看到的那样,添加更多 GPU 或 CPU 并不会在某个点之后添加更多模拟时间步。 Frontier 节点可以在每个 GPU 上模拟大约 100,000 个原子,并且具有强大的缩放能力,并且缩放在大约 32 个 GPU 时停止。因此,Frontier 中的其他 37,856 个 GPU 对于本次测试来说毫无用处。
Lawrence Livermore 的 Quartz 机器拥有 3,018 个节点,每个节点都有一对来自 Intel 的 18 核“Broadwell”Xeon E5-2695 v4 处理器,以及一个 100 Gb/秒的 Omni-Path 网络。这不是速度恶魔,但也不是马虎。 TriLabs 研究人员表示,他们可以模拟每个 CPU 插槽约 1,000 个原子,并且在 400 个节点(800 个插槽)处,扩展性也会逐渐减弱。
所有这些都给我们带来了下一个问题,也是我们在简报中嘲笑 Cerebras 联合创始人兼首席执行官的一个问题:当你将多个晶圆级引擎连接在一起并尝试运行相同的模拟时会发生什么。费尔德曼说目前还没有人知道。
WSE-2 系统中的专有互连可以扩展到 192 个设备,而使用 WSE-3,该数字增加了一个数量级以上,达到 2,048 个设备。当然,这是相当不错的弱扩展,但我们强烈怀疑,同样的扩展原则也适用于 WSE,就像适用于 GPU 和 CPU 一样。你可以进行更大的原子聚合,但仍然只能看到未来的几十毫秒。
当然,除非有某种方法可以将 WSE 物理地连接在一起。想象一下,一堆方形 WSE 的边缘像阿米什家具的抽屉或健身房的橡胶垫一样相互衔接。你可以用相互连接的 WSE 的正方形制作一个烟囱,它们在边缘相互连接,并在烟囱内部运行电源,在烟囱外部冷却。强扩展的有效性将仅限于 WSE 边缘的互连以及从管道顶部到管道底部的走线长度。但有一件事我们可以肯定:这种配置不会比使用 InfiniBand 或以太网连接 CPU 或 GPU 更糟糕。
本站全部资讯来源于实验室原创、合作机构投稿及网友汇集投稿,仅代表个人观点,不作为任何依据,转载联系作者并注明出处:https://www.lvsky.net/78.html
评论