深度神经网络的成功取决于能否获得高质量的标记训练数据,因为训练数据中存在的标签错误(标签噪声)会大大降低模型在干净测试数据上的准确性。不幸的是,大型训练数据集几乎总是包含带有不准确或不正确标签的示例。这导致了一个悖论:一方面,大型数据集对于训练更好的深度网络是必不可少的,而另一方面,深度网络往往会记住训练标签噪声,导致模型在实践中表现较差。
研究界已经认识到这一问题的重要性,并推出了一些试图理解嘈杂训练标签的研究(例如Arpit 等人的研究),以及克服这些问题的缓解策略(例如MentorNet或共同教学)。通过研究噪声水平(数据集中带有错误标签的示例的百分比)对模型性能的影响,对照实验在理解噪声标签方面起着至关重要的作用。然而,目前的实验仅在合成标签上进行,其中噪声示例具有随机分配的标签,而不是遵循不同噪声分布的真实世界标签噪声。与实际经验相比,此类研究可能会得出关于噪声标签的截然不同甚至相互矛盾的发现。此外,在合成噪声上表现良好的方法在现实世界的噪声标签上可能效果不佳。
在ICML 2020上发表的 《超越合成噪声:受控噪声标签上的深度学习》中,我们为更好地理解非合成噪声标签上的深度学习做出了三点贡献。首先,我们建立了第一个受控数据集和来自网络的真实世界标签噪声基准(即网络标签噪声)。其次,我们提出了一种简单但高效的方法来克服合成和现实世界的噪声标签。最后,我们进行了迄今为止最大规模的研究,在各种设置中比较了合成和网络标签噪声。
合成与真实世界(网络)标签噪声的属性 合成
与真实世界(网络)标签噪声图像的分布存在许多差异。首先,带有网络标签噪声的图像在视觉或语义上往往与真正的阳性图像更加一致。其次,合成标签噪声处于类别级别(同一类别中的所有示例都同样嘈杂),而真实世界标签噪声处于实例级别(某些图像比其他图像更容易被错误标记,无论相关类别如何)。例如,从侧面拍摄“本田思域”和“本田雅阁”的图像时,与从正面拍摄车辆时相比,它们更容易混淆。第三,带有真实世界标签噪声的图像来自开放类别词汇表,可能与特定数据集的类别词汇表不重叠。例如,“瓢虫”的网络噪声图像包括“苍蝇”等类别和其他未包含在所用数据集类别列表中的虫子。受控标签噪声的基准将有助于更好地定量理解合成和现实世界的网络标签噪声之间的差异。
来自网络的受控标签噪声基准
本研究的基准建立在两个公共数据集上:Mini-ImageNet(用于粗粒度图像分类)和Stanford Cars (用于细粒度图像分类)。我们遵循构建合成数据集的标准方法,逐步用从网络收集的带错误标签的图像替换这些数据集中的干净图像。
为此,我们使用类名(例如“瓢虫”)作为关键字从网络上收集图像 — 这是一种无需人工注释即可从网络上自动收集带噪声标记图像的方法。然后,每张检索到的图像都会由 3-5 名注释者使用Google Cloud Labeling Service进行检查,他们会确定给出的网络标签是否正确,最终产生近 213k 张带注释的图像。我们使用这些带有错误标签的网络图像替换原始 Mini-ImageNet 和 Stanford Cars 数据集中一定比例的干净训练图像。我们创建了 10 个不同的数据集,标签噪声水平逐渐增加(从 0% 的干净数据到 80% 的数据带有错误标签)。这些数据集已在我们的受控噪声网络标签网站上开源。
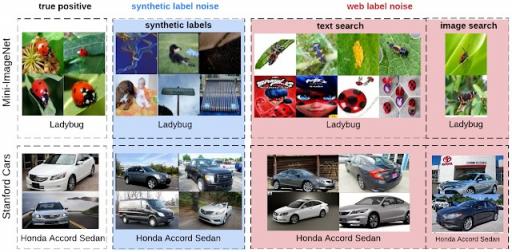
合成标签噪声和网络标签噪声的比较。从左到右,列是 Mini-ImageNet 或 Stanford Cars 数据集中的真正例图像、带有错误合成标签的图像以及带有错误网络标签的图像(在本研究中收集)。
MentorMix:一种简单的稳健学习方法
给定一个噪声水平未知的数据集,我们的目标是训练一个可以很好地泛化干净测试数据的稳健模型。我们引入了一种简单而有效的方法来处理合成和现实世界的噪声标签,称为 MentorMix,这是我们在受控噪声网络标签数据集上开发的。
MentorMix 是一种基于两种现有技术MentorNet和Mixup 的迭代方法,包括四个步骤:加权、采样、混合和再次加权。在第一步中,MentorNet 网络为小批量中的每个示例计算一个权重,该权重可以根据手头的任务进行定制,然后将权重归一化为一个分布。在实践中,目标是为正确标记的示例分配高权重,为错误标记的示例分配零权重。实际上,我们不知道哪些是正确的,哪些是错误的,所以 MentorNet 权重基于近似值。在此处的示例中,MentorNet 使用 StudentNet 训练损失来确定分布中的权重。
接下来,对于每个示例,我们使用重要性抽样根据分布选择同一小批中的另一个示例。由于权重较高的示例往往具有正确的标签,因此在抽样过程中它们更受青睐。然后我们使用 Mixup 混合原始示例和采样示例,以便模型在两者之间进行插值并避免过度拟合嘈杂的训练示例。最后,我们可以为混合示例计算另一个权重来调整最终损失。对于高噪声水平,第二种加权策略的影响变得更加明显。
从概念上讲,上述步骤实现了一种新的稳健损失,事实证明,这种损失对嘈杂的训练标签更具弹性。有关此主题的更多讨论可以在我们的论文中找到。下面的动画说明了 MentorMix 中的四个关键步骤,其中 StudentNet 是在嘈杂的标记数据上进行训练的模型。我们采用了Jiang 等人描述的非常简单的 MentorNet 版本来计算每个示例的权重。
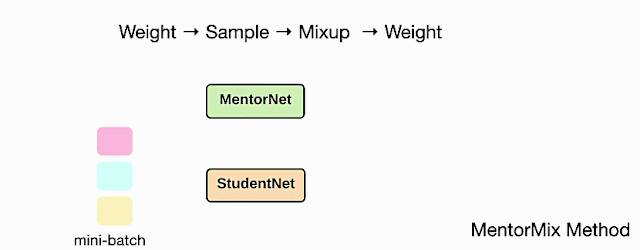
MentorMix 方法中的四个步骤的说明:称重、取样、混合和再次称重。
评估
我们在五个数据集上评估了 MentorMix,包括带有合成标签噪声的CIFAR 10/100和WebVision 1.0 (一个包含 220 万张带有真实世界噪声标签的图像的大型数据集)。MentorMix 在 CIFAR 10/100 数据集上持续获得改进的结果,并在 WebVision 数据集上取得了最佳发布结果,在ImageNet ILSVRC12验证集上的 top-1 分类准确率方面,将之前的最佳方法提高了约 3% 。
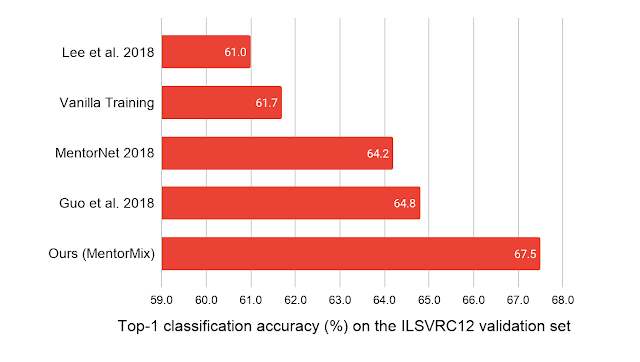
我们的模型仅在 WebVision 220 万个嘈杂训练样本上进行训练,并在 ImageNet ILSVRC12 验证集上进行测试。报告的基线模型是(Lee 等人 2018 年)、(MentorNet 2018 年)和(Guo 等人 2018 年)。
网络上关于噪声标签的新发现
这项研究是迄今为止对噪声标签训练的深度神经网络的最大规模研究。我们提出了关于网络标签噪声的三个新发现:
深度神经网络在网络标签噪声方面有更好的泛化能力
众所周知,深度神经网络在合成标签噪声方面的泛化能力较差,但我们的结果表明,深度神经网络在网络标签噪声方面的泛化能力要好得多。例如,使用 60% 网络标签噪声水平在斯坦福汽车数据集上训练的网络的分类准确率为 0.66,远高于在相同 60% 合成噪声水平下训练的同一网络的准确率,后者仅达到 0.09。这种模式在我们两个数据集中使用微调和从头开始训练时都是一致的。
当对网络标签噪声进行训练时,深度神经网络可能不会首先学习模式
我们的共识是,深度神经网络首先学习模式— 这是一个有趣的特性,DNN 能够在早期训练阶段自动捕获可泛化的“模式”,然后再记住嘈杂的训练标签。因此,早期停止通常用于对嘈杂数据进行训练。然而,我们的结果表明,在使用带有网络标签噪声的数据集进行训练时,深度神经网络可能不会首先学习模式,至少对于细粒度分类任务而言是这样,这表明早期停止可能对来自网络的真实标签噪声无效。
当网络经过微调时,ImageNet 架构可以泛化嘈杂的训练标签
Kornblith 等人 (2019)发现,在 ImageNet 上训练的更高级架构经过微调后,往往在具有干净训练标签的下游任务中表现更好。我们的结果将这一发现扩展到嘈杂的训练数据,表明在 ImageNet 上进行预训练时表现更好的预训练架构即使在嘈杂的训练标签上进行微调时也可能表现更好。
摘要
根据我们的研究结果,我们针对在噪声数据上训练深度神经网络提出了以下实用建议。
处理噪声标签的一个简单方法是微调在干净数据集(如 ImageNet)上预先训练的模型。预训练模型越好,它在下游噪声训练任务上的泛化能力就越强。
早期停止可能对来自网络的真实世界的标签噪声无效。
在合成噪声上表现良好的方法可能在来自网络的真实世界的噪声标签上效果不佳。
来自网络的标签噪音似乎危害较小,但对于我们目前的稳健学习方法来说,处理起来更困难。这鼓励我们在未来对受控的现实世界标签噪音进行更多研究。
所提出的 MentorMix 可以更好地克服合成和现实世界的噪声标签。
MentorMix 的代码可以在GitHub上找到,数据集在我们的数据集网站上。
致谢
本研究由 Lu Jiang、Di Huang、Mason Liu 和 Weilong Yang 进行。我们要感谢 Boqing Gong 和 Fei Sha 提供的建设性反馈。还要感谢领导 Andrew Moore 对我们数据标记工作的支持,以及 Tomas Izo 和 Rahul Sukthankar 在发布数据集方面提供的帮助。
评论