大多数人都认为从多个不同角度观察物体是理所当然的,但仍然能识别出它是同一个物体——从正面看的狗从侧面看仍然是狗。虽然人们很自然地会这样做,但计算机科学家需要明确地让机器学习视角不变的表示,目标是寻找能够保留对下游任务有用的信息的稳健数据表示。
当然,为了学习这些表示,可以使用手动注释的训练数据。然而,在很多情况下这样的注释是不可用的,这就产生了一系列不需要手动注释的训练数据的自监督和跨模态监督方法。目前,使用此类数据进行训练的一个流行范例是多视角对比学习,其中同一场景的两个视图(例如,不同的图像通道、同一图像的增强以及视频和文本对)将倾向于在表示空间中收敛,而不同场景的两个视图则会发散。尽管它们取得了成功,但仍有一个重要的问题:“如果没有现成的带注释的标签,如何选择表示应该保持不变的视图?”换句话说,如何使用图像本身像素中的信息来识别物体,同时从不同视点查看该图像时仍然保持准确?
在“什么是对比学习的良好视角”一文中,我们使用理论和实证分析来更好地理解视角选择的重要性,并认为应该在保持任务相关信息完整的同时减少视角之间的相互信息。为了验证这一假设,我们设计了无监督和半监督框架,旨在通过减少相互信息来学习有效视角。我们还将数据增强视为减少相互信息的一种方法,并表明增加数据增强确实会减少相互信息,同时提高下游分类准确性。为了鼓励在该领域的进一步研究,我们已经开源了代码和预训练模型。
InfoMin 假设

对比多视图学习的目标是学习一个参数编码器,其输出表示可用于区分具有相同身份的视图对和具有不同身份的视图对。视图之间共享的信息量和类型决定了生成的模型在下游任务上的表现。我们假设,产生最佳结果的视图应该尽可能多地丢弃输入中的信息,除了与任务相关的信息(例如,对象标签),我们称之为InfoMin 原则。
考虑下面的示例,其中同一图像的两个块代表不同的“视图”。训练目标是识别两个视图是否属于同一图像。视图共享的信息过多是不可取的,例如,低级颜色和纹理线索可用作“捷径”(左),视图共享的信息太少,无法识别它们属于同一图像(右)。相反,“最佳点”的视图共享与下游任务相关的信息,例如,对象分类任务中对应于熊猫不同部位的块(中间)。
对比多视图学习期间捕获的三种信息模式的图示。视图不应共享过多信息(左)或过少信息(右),而应找到一个最佳组合(“最佳点”,中间),以最大化下游性能。
对比学习的统一观点
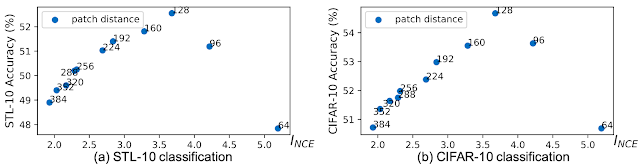
我们设计了几组实验来验证 InfoMin 假设,其动机是存在简单的方法可以在没有任何监督的情况下控制视图之间共享的相互信息。例如,我们可以从同一幅图像中采样不同的块,并通过增加块之间的距离来减少它们的相互信息。在这里,我们使用InfoNCE(I NCE)来估计相互信息,它是相互信息下限的定量度量。事实上,我们观察到一个倒 U 形曲线:随着相互信息的减少,下游任务准确率首先增加然后开始下降。
通过在对比学习的表示上应用线性分类器,实现STL-10(左)和CIFAR-10(右)上的下游分类准确率。与上图相同,视图被采样为来自同一图像的不同块。增加块之间的欧几里得距离会导致互信息减少。观察到分类准确率和I NCE(块距离)之间的倒 U 形曲线。
此外,我们证明了几种最先进的对比学习方法(InstDis、MoCo、CMC、PIRL、SimCLR和CPC)可以通过视图选择的视角统一:尽管在架构、目标和工程细节上存在差异,但所有最近的对比学习方法都创建了两个视图,这些视图隐含地遵循 InfoMin 假设,其中视图之间共享的信息由数据增强的强度控制。受此启发,我们提出了一组新的数据增强,其在 ImageNet线性读出基准上的表现比之前最先进的SimCLR高出近 4% 。我们还发现,将我们的无监督预训练模型转移到对象检测和实例分割上的表现始终优于 ImageNet 预训练。
学习生成视图
在我们的工作中,我们设计了无监督和半监督方法,根据 InfoMin 假设合成新视图。我们学习基于流的模型,将自然色彩空间转换为新色彩空间,从中分割通道以获取视图。对于无监督设置,视图生成器经过优化,以最小化视图之间的 InfoNCE 边界。如下面的结果所示,我们在最小化 InfoNCE 边界的同时观察到类似的倒 U 形趋势。
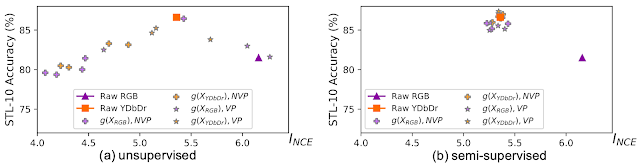
查看通过无监督(左)和半监督(右)目标学习的生成器。
为了在不过度最小化互信息的情况下达到最佳点,我们可以使用半监督设置并引导视图生成器保留标签信息。正如预期的那样,无论输入颜色空间是什么,所有学习到的视图现在都以最佳点为中心。
代码和预训练模型
为了加速自监督对比学习的研究,我们很高兴与学术界分享 InfoMin 的代码和预训练模型。它们可以在这里找到。
致谢
核心团队包括 Yonglong Tian、Chen Sun、Ben Poole、Dilip Krishnan、Cordelia Schmid 和 Phillip Isola。我们要感谢 Kevin Murphy 的深刻讨论;感谢 Lucas Beyer 对稿件的反馈;感谢 Google Cloud 团队的计算支持。
评论