卷积神经网络(CNN) 的成功主要源于卷积的两个特性:平移等变性和局部性。平移等变性虽然并不完全准确,但它能确保模型对图像中不同位置的物体或不同大小的图像都能很好地发挥作用。局部性能确保计算效率,但代价是难以对大图像的全景分割进行长距离空间关系建模。例如,分割一个大物体需要对其形状进行建模,这可能会覆盖非常大的像素区域,而有助于分割该物体的上下文可能来自更远的地方。在这种情况下,无法从远离卷积核的上下文中通知模型可能会对性能产生负面影响。
大量文献讨论了解决局部性限制和实现 CNN 中长距离交互的方法。一些方法采用了空洞卷积或图像金字塔,它们在一定程度上扩大了感受野,但仍然局限于一小块局部区域。另一项工作采用了自注意机制,例如非局部神经网络,与局部卷积相反,它允许感受野覆盖整个输入图像。不幸的是,这种方法在计算上很昂贵,特别是对于大量输入而言。最近的研究可以构建完全注意模型,但代价是将局部约束应用于非局部神经网络。这些限制限制了模型感受野,这对分割等任务是有害的,特别是在高分辨率输入上。
在我们最近的ECCV 2020论文“ Axial-DeepLab:用于全景分割的独立轴向注意力”中,我们建议采用轴向注意力(或交叉注意力),它可以在完全注意模型中恢复大感受野。核心思想是将二维注意力分成两个步骤,依次在高度和宽度轴上应用一维注意力。这种方法的效率可以实现对大区域的注意力,让模型可以学习长距离甚至全局的交互。此外,我们提出了一种新颖的自注意力模块公式,它对大感受野中相关上下文的位置更敏感,而且边际成本较低。我们将位置敏感的轴向注意力方法应用于Panoptic-DeepLab,一种简单有效的全景分割方法,来评估它在全景分割上的效果。我们的模型的有效性在ImageNet、COCO和Cityscapes上得到了证明。 Axial-DeepLab 在全景分割和语义分割方面取得了最佳成果,大大 超越了Panoptic-DeepLab 。
Axial-Attention 架构
Axial-DeepLab 由 Axial-ResNet 主干和Panoptic-DeepLab输出头组成,可产生全景分割结果。我们的 Axial-ResNet 建立在ResNet 架构上,其中ResNet 瓶颈块中的所有3×3局部卷积都被我们提出的全局位置敏感轴向注意力所取代,从而实现了较大的感受野和精确的位置信息。
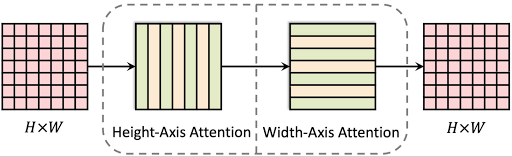
轴向注意块由两个位置敏感的轴向注意层组成,沿高度和宽度轴顺序操作。
Axial-DeepLab高度轴向注意层全局提供 1 维自注意,在各个列内传播信息 — 它不会在列之间传输信息。在水平方向上运行的第二个 1D 注意层允许捕获列方向和行方向的信息。这种分离将自注意的复杂性从二次 (2D) 降低到线性 (1D),这使得全景分割中的远程建模可以在所有层中使用更大的 (65×65 对比之前的 3×3) 甚至全局上下文。
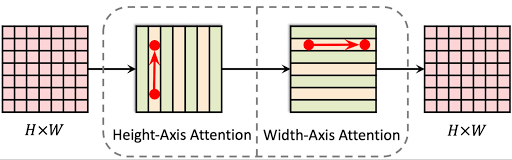
一条消息可以通过两跳在全球范围内传递。
请注意,( x 1, y 1) 处的消息或特征向量始终可以在 2D 网格上全局传递到任何位置 (x2, y2),在高度轴上跳跃一次 ( x 1, y 1 → x 1, y 2),然后在宽度轴上再跳跃一次 ( x 1, y 2 → x 2, y 2)。通过这种方式,我们能够在单个残差块中对 2D 长距离关系进行建模。这种轴向注意力设计还将复杂性从二次降低到线性,并在模型的所有层中实现全局感受野。
位置敏感的自注意力
此外,我们提出了一种位置敏感的自注意力公式。先前的自注意力公式使给定的像素A能够聚合长距离上下文B,但没有提供有关上下文在感受野中起源位置的信息。例如,像素A处的特征可能代表猫的眼睛,而上下文B可能是鼻子和另一只眼睛。在这种情况下,无论脸部的几何结构如何,像素A处的聚合特征将是鼻子和两只眼睛。当两只眼睛位于图像的左下方而鼻子位于右上方时,可能会导致错误地指示脸部存在。最近提出的解决方案是对上下文在感受野中可能起源的位置施加位置偏差。这种偏差仅取决于A处的特征(眼睛),而不取决于包含重要上下文信息的 B 处的特征。
在本研究中,我们让这个偏差也依赖于B 处的上下文特征(即鼻子和另一只眼睛)。当像素和通知它的上下文彼此相距甚远并因此包含有关偏差的不同信息时,此更改可以实现更准确的位置偏差。此外,当像素A聚合上下文特征B时,我们还包括一个指示从A到B 的相对位置的特征。此更改使A能够准确地知道B 的来源。这两个变化使自注意力具有位置敏感性,尤其是在远程建模的情况下。
结果我们在COCO和Cityscapes
上测试了 Axial-DeepLab 的全景分割。下表显示了每个数据集相对于最先进的Panoptic-DeepLab 的改进。特别是,在 COCO 测试开发集上,我们的 Axial-DeepLab 的全景质量 (PQ) 比 Panoptic-DeepLab 高出 2.8%。我们的单尺度小模型比多尺度 Panoptic-DeepLab 表现更好,同时计算效率提高了 27 倍,并且仅使用 1/4 的参数数量。我们还在 Cityscapes 上展示了最先进的结果。此外,我们发现随着块感受野从 5×5 增加到 65×65,性能也会提高。我们的模型对未在其上训练的分布外尺度也更具鲁棒性。
模型 可可 城市景观
Panoptic-DeepLab 39.7 65.3
Axial-DeepLab(我们的) 43.4 (+3.7) 66.5 (+1.2)
在验证集上与 Panoptic-DeepLab 进行单尺度比较
除了我们在全景分割方面的主要结果之外,我们的完整轴注意模型 Axial-ResNet 也比之前在 ImageNet 上最好的独立自注意模型表现更好。
模型 参数 M-添加 前 1 名
ResNet-50 25.6百万 4.1B 76.9
独立 1800万 3.6B 77.6
完全轴向注意力(我们的) 12.5米 3.3B 78.1
Full Axial-Attention 在 ImageNet 上也运行良好。
结论
我们提出并证明了位置敏感轴向注意力在图像分类和全景分割方面的有效性。在 ImageNet 上,我们通过堆叠轴向注意力块形成的 Axial-ResNet 在独立的自注意力模型中取得了最先进的结果。我们进一步将 Axial-ResNet 转换为 Axial-DeepLab 以进行自下而上的全景分割,并在包括 COCO 和 Cityscapes 在内的多个基准测试中展示了最先进的性能。我们希望我们的有希望的结果能够证明轴向注意力是现代计算机视觉模型的有效构建块。
致谢
这篇文章反映了作者以及 Bradley Green、Hartwig Adam、Alan Yuille 和 Liang-Chieh Chen 的工作。我们还感谢 Niki Parmar 的讨论和支持; Ashish Vaswani、Xuhui Jia、Raviteja Vemulapalli、Zhuoran Shen 提出了富有洞察力的意见和建议; Maxwell Collins 和 Blake Hechtman 提供技术支持。
评论