洪水是地球上最常见的自然灾害,影响着全球数亿人的生活,每年造成约 100 亿美元的损失。基于前几年的工作,本周早些时候,我们宣布了近期为改善印度和孟加拉国的洪水预报所做的一些努力,将覆盖范围扩大到 2.5 亿多人,并提供了前所未有的提前量、准确性和清晰度。
为了实现这些突破,我们设计了一种新的洪水建模方法,称为形态洪水模型,它将基于物理的建模与机器学习 (ML) 相结合,以在现实环境中创建更准确、更可扩展的洪水模型。此外,我们的新警报定位模型允许使用端到端机器学习模型和全球公开的数据,以前所未有的规模识别面临洪水风险的区域。在本文中,我们还介绍了下一代洪水预报系统 HydroNets (今年在ICLR 地球科学人工智能和EGU上展示)的发展情况,这是一种专为跨多个流域的水文建模而构建的新架构,同时仍在优化每个位置的准确性。
预测水位
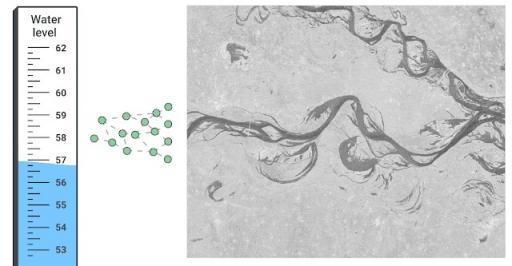
洪水预报系统的第一步是确定河流是否会发生洪水。长期以来,政府和灾害管理机构一直使用水文模型(或水位测量模型)来提高预报的准确性和延长预报时间。这些模型接收降水量或上游水位测量值(即水位高于海平面的绝对高度)等输入,并输出未来某个时间河流水位(或流量)的预测。
本周关键词文章中描述的洪水预报系统的水文模型组件将覆盖 7500 多万人口的地区的洪水警报提前时间延长了一倍。这些模型不仅增加了提前时间,而且还提供了前所未有的准确性,在我们覆盖的所有流域中实现了超过 99% 的R 2得分,并且 90% 以上的时间都能预测在 15 厘米误差范围内的水位。一旦预测河流将达到洪水水位,生成可操作警告的下一步就是将河流水位预测转化为对洪泛区将如何受到影响的预测。
形态洪水建模
在之前的工作中,我们根据卫星图像开发了高质量的高程地图,并运行基于物理的模型来模拟这些数字地形上的水流,从而能够在数据稀缺的地区以前所未有的分辨率和准确性发出警报。通过与我们的卫星合作伙伴空中客车、Maxar和Planet合作,我们现在已将高程地图扩展到数亿平方公里。然而,为了将覆盖范围扩大到如此大的区域,同时仍保持高精度,我们不得不重新设计开发洪水模型的方式。

洪水模型可估算哪些区域会被淹没以及水深。此可视化从概念上展示了如何模拟洪水、如何定义风险等级(用红色和白色表示)以及如何使用该模型识别应发出警告的区域(绿点)。
大规模洪水建模面临三大挑战。由于涉及的面积大,且此类模型所需的分辨率高,因此计算复杂度必然很高。此外,大多数全球海拔地图不包括河床水深测量,而这对于准确建模至关重要。最后,需要了解和纠正现有数据中的错误,这些错误可能包括测量误差、海拔地图中缺失的特征等。纠正这些问题可能需要收集额外的高质量数据或手动修复错误数据,这两种方法都不太适用。
我们称之为形态模型的洪水建模新方法,通过使用多种创新技巧来解决这些问题。我们不是实时模拟复杂的水流行为,而是计算对海拔图形态的修改,这样人们就可以使用简单的物理原理(例如描述静水系统的原理)来模拟洪水。
首先,我们训练一个纯 ML 模型(不含物理信息),根据水表测量值估算一维河流剖面。该模型将河流上特定点(流量计)的水位作为输入,并输出河流剖面,即河流中所有点的水位。我们假设,如果水表增加,水位单调增加,即河流中其他点的水位也会增加。我们还假设河流剖面的绝对高程向下游降低(即河流向下流动)。
然后,我们使用这个学习模型和一些启发式方法来编辑海拔地图,以大致“抵消”该地区被洪水淹没时可能存在的压力梯度。这张新的合成海拔地图为我们使用简单的洪水填充算法模拟洪水行为提供了基础。最后,我们将生成的洪水地图与基于卫星的洪水范围与原始流量计测量值进行匹配。
这种方法摒弃了经典物理模型 的一些现实限制,但在现有方法目前难以应对的数据稀缺地区,其灵活性使模型能够自动学习正确的水深测量并修复物理模型敏感的各种错误。这种形态模型将准确度提高了 3%,这可以显著改善大面积区域的预测,同时还可以通过减少手动建模和校正的需要来更快地开发模型。
警报定位
许多人居住在形态淹没模型未覆盖的地区,但仍然迫切需要获得准确的预测。为了覆盖这些人群并提高洪水预报模型的影响力,我们设计了一种基于 ML 的端到端方法,几乎只使用全球公开的数据,例如流量计测量值、公共卫星图像和低分辨率高程图。我们训练模型使用接收到的数据直接推断实时淹没地图。
从实时测量到淹没的直接 ML 方法。
当模型只需要预测之前观察到的事件范围内的事件时,这种方法“开箱即用”效果很好。推断更极端的情况要困难得多。尽管如此,正确使用现有的海拔地图和实时测量可以为更详细的形态淹没模型未覆盖的地区提供比目前更准确的警报。由于该模型具有高度可扩展性,我们仅用了几个月就能够在印度各地推出它,我们希望很快将其推广到更多国家。
改进水位预报
为了继续改进洪水预报,我们开发了HydroNets——一种专门为水位预报而构建的专用深度神经网络架构——它使我们能够在现实世界的操作环境中利用基于 ML 的水文学领域一些令人兴奋的最新进展。它有两个突出的特点与标准水文模型不同。首先,它能够区分在站点之间具有良好泛化的模型组件,例如降雨径流过程的建模,以及特定于给定站点的模型组件,例如评级曲线,它将预测的排放量转换为预期的水位。这使得模型能够很好地推广到不同的站点,同时仍可针对每个位置微调其性能。其次,HydroNets 考虑了正在建模的河流网络的结构,通过训练一个大型架构,该架构实际上是一个由较小的神经网络组成的网络,每个神经网络代表河流沿线的不同位置。这使得对上游站点进行建模的神经网络能够将嵌入中编码的信息传递给下游站点的模型,这样每个模型都可以知道它需要的一切,而无需大幅增加参数。
下面的动画展示了 HydroNets 中信息的结构和流动。上游子流域建模的输出被组合成给定流域状态的单一表示。然后由共享模型组件处理,该组件由网络中的所有流域提供信息,并传递给标签预测模型,该模型计算水位(和损失函数)。然后,网络此迭代的输出被传递以通知下游模型,依此类推。

HydroNets 架构的图示。
我们对这一进展感到非常兴奋,并正在努力进一步改进我们的系统。
致谢这项工作是 Google 洪水预报计划、Google 地理和危机响应团队、Google.org
和 Google 的许多其他研究团队合作的成果,也是我们AI for Social Good工作的一部分。我们还要感谢合作伙伴和政策团队。
评论