强化学习 (RL) 是一种使用反复试验来训练代理在复杂环境中按顺序做出决策的范例,它在游戏、机器人操控和芯片设计等多个领域都取得了巨大成功。代理通常旨在最大化它们在环境中收集的奖励总和,这可以基于多种参数,包括速度、好奇心、美学等。然而,设计一个特定的 RL 奖励函数是一项挑战,因为它可能很难指定或过于稀疏。在这种情况下,模仿学习(IL) 方法提供了一种替代方案,因为它们从专家演示中学习如何解决任务,而不是精心设计的奖励函数。然而,最先进的 IL 方法依赖于对抗性训练,它使用最小/最大优化程序,这使得它们在算法上不稳定且难以部署。
在“原始 Wasserstein 模仿学习”(PWIL)中,我们引入了一种新的 IL 方法,该方法基于Wasserstein 距离的原始形式(也称为地球移动距离),不依赖于对抗性训练。使用MuJoCo 任务套件,我们通过有限数量的演示(甚至单个示例)和与环境的有限交互来模仿模拟专家,从而证明了 PWIL 方法的有效性。

左图:算法人形“专家”的演示,根据任务的真实奖励(与速度有关)进行训练。右图:使用 PWIL 进行专家演示训练的代理。
对抗性模仿学习
最先进的对抗性 IL 方法的运行方式类似于生成对抗网络(GAN),其中生成器 (策略)被训练为最大化鉴别器 (奖励)的混淆度,而鉴别器本身被训练为区分代理的状态-动作对和专家的状态-动作对。对抗性 IL 方法归结为分布匹配问题,即最小化度量空间中概率分布之间距离的问题 。然而,与 GAN 一样,对抗性 IL 方法依赖于最小/最大优化问题,因此带来了许多训练稳定性挑战。
模仿学习作为分布匹配
PWIL 方法基于将 IL 公式化为分布匹配问题,在本例中为 Wasserstein 距离。第一步是从演示中推断出专家的状态-动作分布,即专家采取的动作与相应环境状态之间的关系集合。然后,目标是通过与环境的交互来最小化代理和专家的状态-动作分布之间的距离。相比之下,PWIL 是一种非对抗性方法,使其能够绕过最小/最大优化问题并直接最小化代理和专家的状态-动作对分布之间的 Wasserstein 距离。
原始 Wasserstein 模仿学习
计算精确的 Wasserstein 距离可能会受到限制,因为必须等到代理轨迹结束才能计算它,这意味着只有当代理完成与环境的交互后才能计算奖励。为了避免这种限制,我们使用距离的上限,从中我们可以定义使用 RL 优化的奖励。我们表明,通过这样做,我们确实恢复了专家行为,并在 MuJoCo 模拟器的一系列运动任务中最小化了代理和专家之间的 Wasserstein 距离。虽然对抗性 IL 方法使用来自神经网络的奖励函数,该函数必须在代理与环境交互时不断优化和重新估计,但 PWIL 从演示中离线定义了一个奖励函数,它不会改变,并且基于比对抗性 IL 方法少得多的超参数。
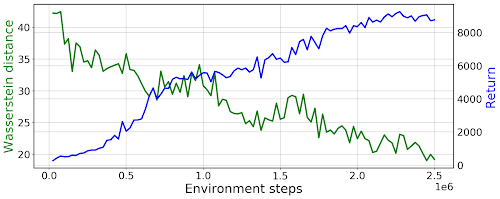
Humanoid上的 PWIL 训练曲线。绿色表示专家状态-动作分布的 Wasserstein 距离。蓝色表示代理的回报(收集到的奖励总和)。
真实模仿学习环境的相似性度量
与 ML 中的众多挑战一样,许多 IL 方法都是在合成任务上进行评估的,在这些任务中,通常可以访问任务的底层奖励函数,并且可以衡量专家和代理行为在绩效方面的相似性,这是预期的奖励总和。PWIL 的副产品是创建了一个指标,该指标可以将专家行为与代理的行为进行比较,适用于任何 IL 方法,而无需访问任务的真实奖励。从这个意义上讲,我们可以在真实的 IL 设置中使用 Wasserstein 距离,而不仅仅是在合成任务上。
结论
在交互成本高昂的环境中(例如,真实机器人或复杂的模拟器),PWIL 是首选,不仅因为它可以恢复专家行为,还因为它定义的奖励函数易于调整,并且无需与环境交互即可定义。这为未来的探索打开了多种机会,包括部署到真实系统、将 PWIL 扩展到我们只能访问演示状态(而不是状态和动作)的设置,以及最终将 PWIL 应用于基于视觉的观察。
致谢
我们感谢我们的合著者 Matthieu Geist 和 Olivier Pietquin;以及 Zafarali Ahmed、Adrien Ali Taïga、Gabriel Dulac-Arnold、Johan Ferret、Alexis Jacq 和 Saurabh Kumar 对手稿的反馈。
评论