在过去十年中,强化学习(RL) 已成为机器学习中最有前途的研究领域之一,并已显示出在解决复杂的现实问题(例如芯片布局和资源管理)以及解决具有挑战性的游戏(例如围棋、Dota 2和捉迷藏)方面的巨大潜力。 简单来说,RL 基础设施是一个数据收集和训练的循环,其中参与者探索环境并收集样本,然后将这些样本发送给学习者以训练和更新模型。 大多数当前的 RL 技术需要对来自环境的数百万个样本进行多次迭代才能学习目标任务(例如,Dota 2 每 2 秒从 200 万帧的批次中学习)。 因此,RL 基础设施不仅应该有效扩展(例如增加参与者的数量)并收集大量样本,还能够在训练期间快速迭代这些大量样本。
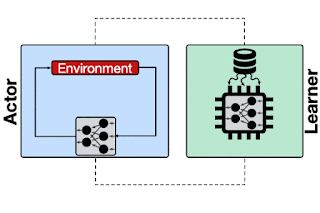
强化学习系统概述,其中参与者将轨迹(例如多个样本)发送给学习者。学习者使用采样数据训练模型,并将更新后的模型推送回参与者(例如TF-Agents、IMPALA)。
今天我们介绍 Menger 1,这是一种具有本地推理能力的大规模分布式强化学习基础设施,可扩展到多个处理集群(例如Borg 单元)中的数千个参与者,从而缩短芯片布局任务的总体训练时间。在这篇文章中,我们将介绍如何使用Google TPU 加速器实现 Menger 以进行快速训练迭代,并展示其在芯片布局这一具有挑战性的任务上的性能和可扩展性。与基线实现相比,Menger 将训练时间缩短了 8.6倍。
Menger 系统设计
有各种分布式 RL 系统,例如Acme和SEED RL,每个系统都专注于优化分布式强化学习系统空间中的单个特定设计点。例如,Acme 对每个参与者使用本地推理并从学习者那里频繁检索模型,而 SEED RL 则受益于集中式推理设计,通过分配一部分 TPU 核心来执行批量调用。这些设计点之间的权衡是 (1) 支付向/从集中式推理服务器发送/接收观察和操作的通信成本或支付从学习者检索模型的通信成本,以及 (2) 与加速器(例如 TPU/GPU)相比,参与者(例如 CPU)的推理成本。由于我们的目标应用程序的要求(例如观察、操作和模型大小),Menger 以类似于 Acme 的方式使用本地推理,但将参与者的可扩展性推向了几乎无限的极限。在加速器上实现大规模可扩展性和快速训练的主要挑战包括:
为学习者提供从参与者到模型检索的大量读取请求很容易限制学习者的速度,并且随着参与者数量的增加,很快就会成为一个主要瓶颈(例如,显著增加收敛时间)。
TPU 性能通常受输入管道将训练数据输入 TPU 计算核心的效率限制。随着 TPU 计算核心数量的增加(例如TPU Pod),输入管道的性能对于整体训练运行时间变得更加关键。
高效的模型检索
为了解决第一个挑战,我们在学习者和参与者之间引入了透明的分布式缓存组件,这些组件在 TensorFlow 中进行了优化,并由Reverb提供支持(与Dota中使用的方法类似)。缓存组件的主要职责是在来自参与者的大量请求和学习者作业之间取得平衡。添加这些缓存组件不仅可以显著减轻学习者处理读取请求的压力,还可以将参与者进一步分布在多个Borg 单元上,同时减少通信开销。在我们的研究中,我们表明,对于一个有 512 个参与者的 16 MB 模型,引入的缓存组件将平均读取延迟降低了约 4.0 倍,从而加快了训练迭代速度,尤其是对于PPO等在线策略算法而言。
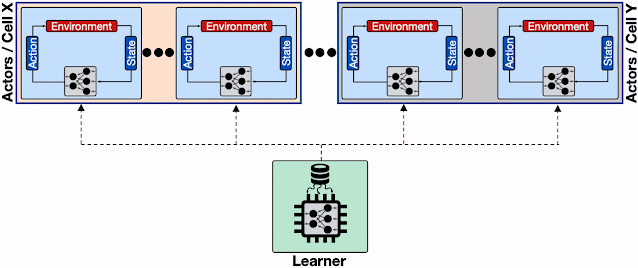
分布式 RL 系统概览,其中多个参与者位于不同的 Borg 单元中。为来自不同 Borg 单元的大量参与者的频繁模型更新请求提供服务会限制学习者以及学习者和参与者之间的通信网络,从而导致整体收敛时间显著增加。虚线表示不同机器之间的gRPC通信。
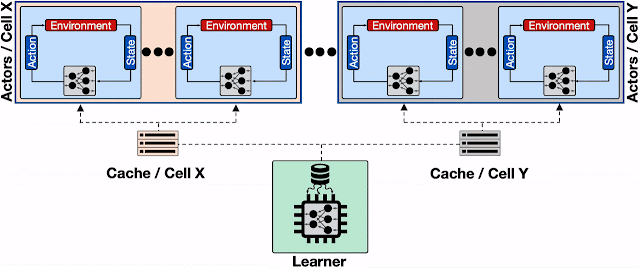
分布式 RL 系统概述,该系统具有多个参与者,放置在不同的 Borg 单元中,并引入了透明的分布式缓存服务。学习者仅将更新后的模型发送到分布式缓存服务。每个缓存服务处理来自附近参与者(即放置在同一个 Borg 单元上的参与者)和缓存服务的模型请求更新。缓存服务不仅减少了学习者为处理模型更新请求而承担的负担,还减少了参与者的平均读取延迟。
高吞吐量输入管道
为了提供高吞吐量输入数据管道,Menger 使用了Reverb,这是一个最近开源的数据存储系统,专为机器学习应用程序而设计,它提供了一个高效灵活的平台,可以在各种在线策略/离线策略算法中实现经验重放。但是,在具有数千名参与者的分布式 RL 设置中,使用单个 Reverb 重放缓冲区服务目前无法很好地扩展,而且在参与者的写入吞吐量方面效率低下。
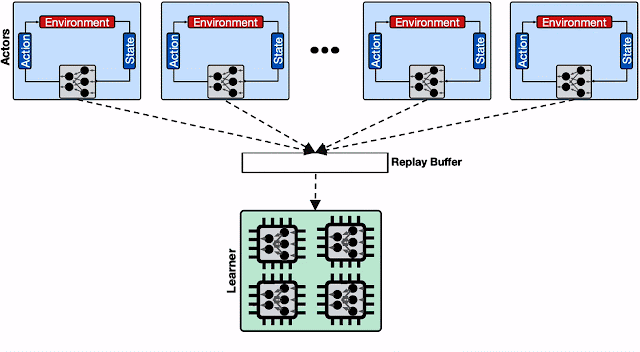
具有单个重放缓冲区的分布式 RL 系统。处理来自参与者的大量写入请求会限制重放缓冲区并降低其总体吞吐量。此外,当我们将学习器扩展到具有多个计算引擎(例如 TPU Pod)的设置时,从单个重放缓冲区服务向这些引擎提供数据变得效率低下,这会对总体收敛时间产生负面影响。
为了更好地了解分布式设置中重放缓冲区的效率,我们评估了各种有效负载大小(从 16 MB 到 512 MB)和参与者数量(从 16 到 2048)的平均写入延迟。当重放缓冲区和参与者放置在同一个Borg单元上时,我们重复了实验。随着参与者数量的增加,平均写入延迟也会显著增加。将参与者的数量从 16 扩展到 2048,有效负载大小 16 MB 和 512 MB 的平均写入延迟分别增加了约 6.2倍和约 18.9倍。写入延迟的增加会对数据收集时间产生负面影响,并导致整体训练时间效率低下。
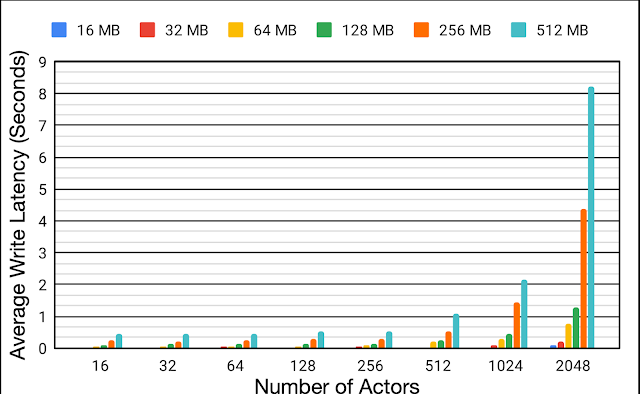
当参与者和重放缓冲区位于同一个 Borg 单元时,单个Reverb重放缓冲区对不同有效载荷大小(16 MB - 512 MB)和不同数量参与者(16 到 2048)的平均写入延迟。
为了缓解这种情况,我们使用Reverb提供的分片功能来增加参与者、学习者和重放缓冲服务之间的吞吐量。分片可以在多个重放缓冲服务器之间平衡大量参与者的写入负载,而不是限制单个重放缓冲服务器,还可以最大限度地减少每个重放缓冲服务器的平均写入延迟(因为共享同一服务器的参与者更少)。这使 Menger 能够有效地扩展到多个 Borg 单元中的数千个参与者。
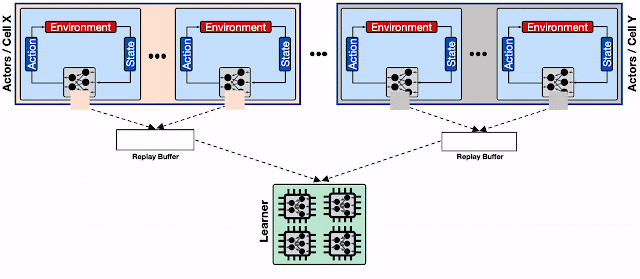
具有分片重放缓冲区的分布式 RL 系统。每个重放缓冲区服务都是一组参与者的专用数据存储,通常位于同一个 Borg 单元上。此外,分片重放缓冲区配置为加速器核心提供了更高吞吐量的输入管道。
案例研究:芯片布局我们研究了 Menger 在大型网络表的芯片布局
这一复杂任务中的优势。与强大的基线相比,Menger 使用 512 个 TPU 核心,在训练时间方面实现了显著的改进(高达约 8.6倍,在最快配置下将训练时间从约 8.6 小时缩短至仅 1 小时)。虽然 Menger 针对 TPU 进行了优化,但实现这一性能提升的关键因素是架构,我们预计在 GPU 上使用时会看到类似的提升。
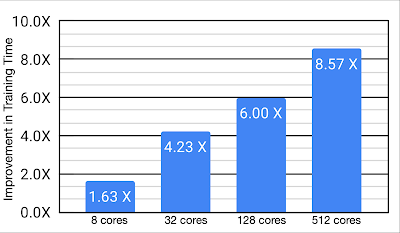
与芯片放置任务的基线相比,使用具有可变数量 TPU 核心的 Menger 可以缩短训练时间。
我们相信,Menger 基础设施及其在复杂的芯片布局任务中取得的良好成果,为进一步缩短芯片设计周期提供了一条创新的道路,不仅有可能推动芯片设计流程的进一步创新,而且还有可能推动其他具有挑战性的现实任务。
致谢
大部分工作由 Amir Yazdanbakhsh、Junchao Chen 和 Yu Zheng 完成。 我们还要感谢 Robert Ormandi、Ebrahim Songhori、Shen Wang、TF-Agents 团队、Albin Cassirer、Aviral Kumar、James Laudon、John Wilkes、Joe Jiang、Milad Hashemi、Sat Chatterjee、Piotr Stanczyk、Sabela Ramos、Lasse Espeholt、Marcin Michalski、Sam Fishman、Ruoxin Sang、Azalia Mirhosseini、Anna Goldie 和 Eric Johnson 的帮助和支持。
评论